如何在 Achelous平台上将作业投递到指定节点
生物信息分析软件在运行过程中,经常面临相对复杂的运行需求。例如,基因组组装任务占用内存较大,且内上限不明确;而另一些科研院所内,不同的项目组的集群队列由相关部门统一管理,需要不同来源的计算任务运行于不同的队列中;有时需要对一部分计算机器进行资源预留,但在计算空闲时需要对一部分小任务能进行计算。Achelous 保证将用户调度到合适的计算节点,可以访问需要的存储和硬件资源。但在某些特殊场景下,用户可能要求计算被调度到指定的计算节点。
情形1:使用"胖节点"
某些生物计算任务需要使用超大内存节点,因此计算任务需要调度到指定的胖节点。用户需要在Task的runtime属性中指定ServerType,例如:
task analysis {
…
command {…}
runtime {
…
servertype: "fat" ### 指明该任务只能在"胖节点" 进行运行
…
}
…
情形2: 指定计算节点的属性
处于某些管理需求,系统管理员可能会将计算服务器分成某些区域或者组,为每个节点打上类似Key/Value对的标签。流程编写者在编写对应的 WDL脚本时,可以通过在Task的runtime属性slaveconstraint或者Job JSON的constraints中指定计算节点需要满足的Key/Value对。例如:
task analysis {
...
command {...}
runtime {
...
slaveconstraint: {
"region" :"region1",
"group" :"group1"
}
...
}
作业提交时,用户在Job的JSON中指定Constraints属性,则这个Job的所有Task将自动具备了对应的SlaveConstraints属性。例如:
{
...
"Constraints":{
"region": "region1",
"group" : "group1"
}
}
上面的Job提交后,则全部任务都会在集群中,对应的 region1和group1 的计算节点上运行。
如果需要指定任务在某个特定节点上运行,则可以在Job文件中指定:
{
"Constraints": { "hostname" : "Cc2BCluster" } ### 通过hostname指定作业
}
情形3:使用 Poros中调度域配置进行作业运行规划
上述两种模式可以在流程编写和任务投递两个层面,对作业运行的具体节点进行了选择。对于更普遍的作业运行约束,Achelous平台也提供了调度域的概念,可供管理员对一组用户进行统一管理。
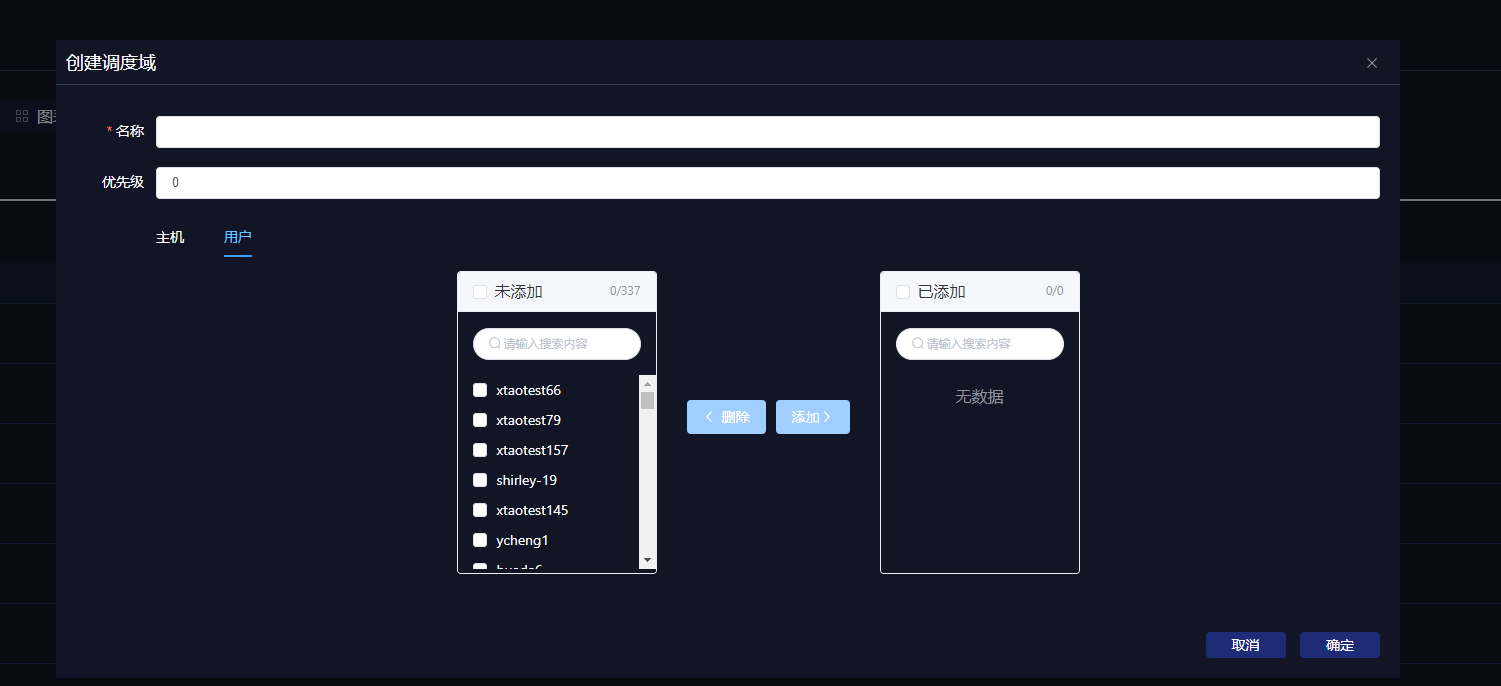
管理员用户通过 Poros界面可以进行调度域的添加和管理。对于某个调度域而言,管理员可以向其中添加一到多个用户。当某用户被添加到调度域中后,其提交的作业会自动投递至对应服务器上运行。
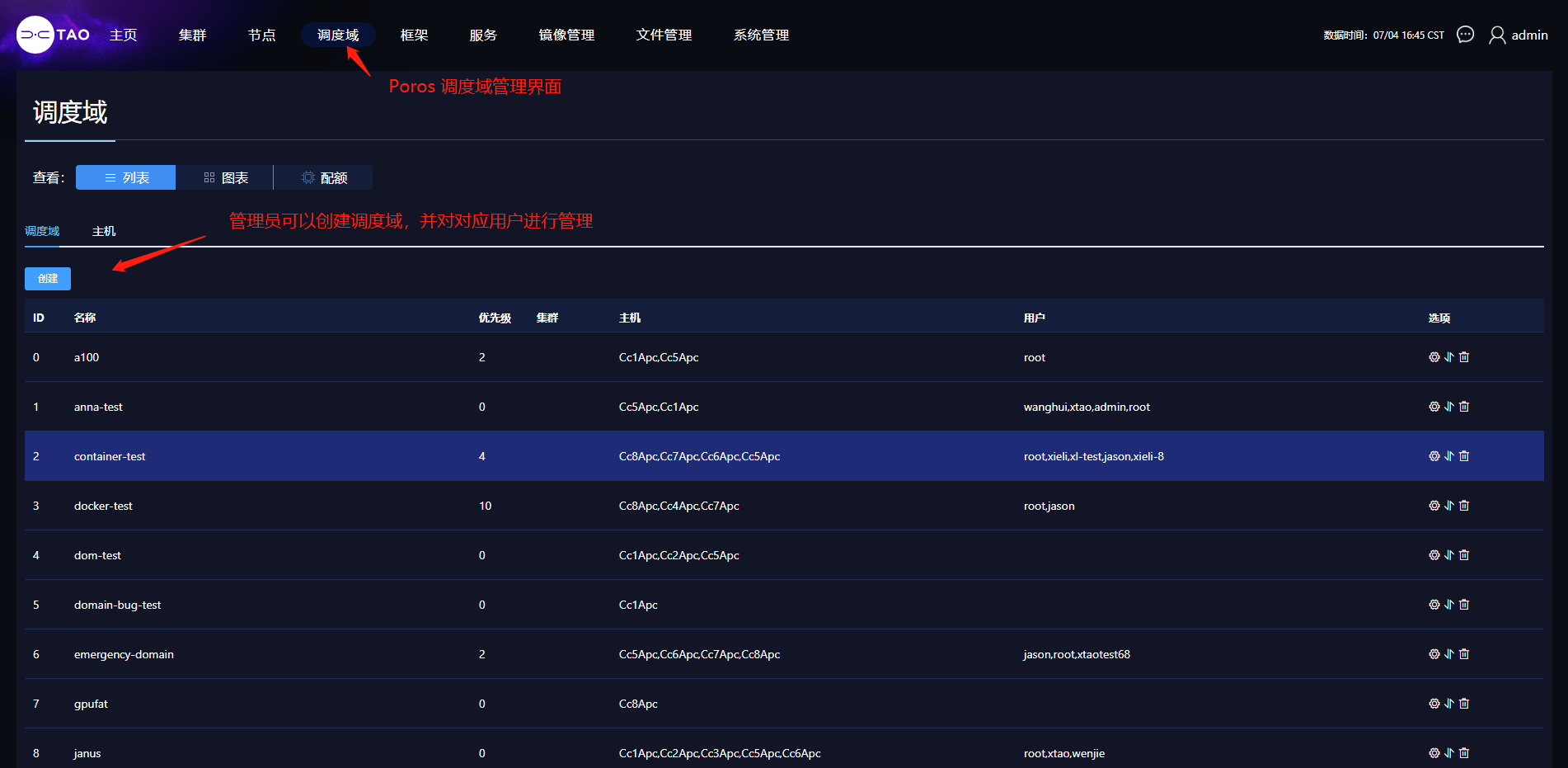
在管理界面中,除了可以配置调度域中相应的服务器,也可以对调度域对应的任务优先级进行定义。
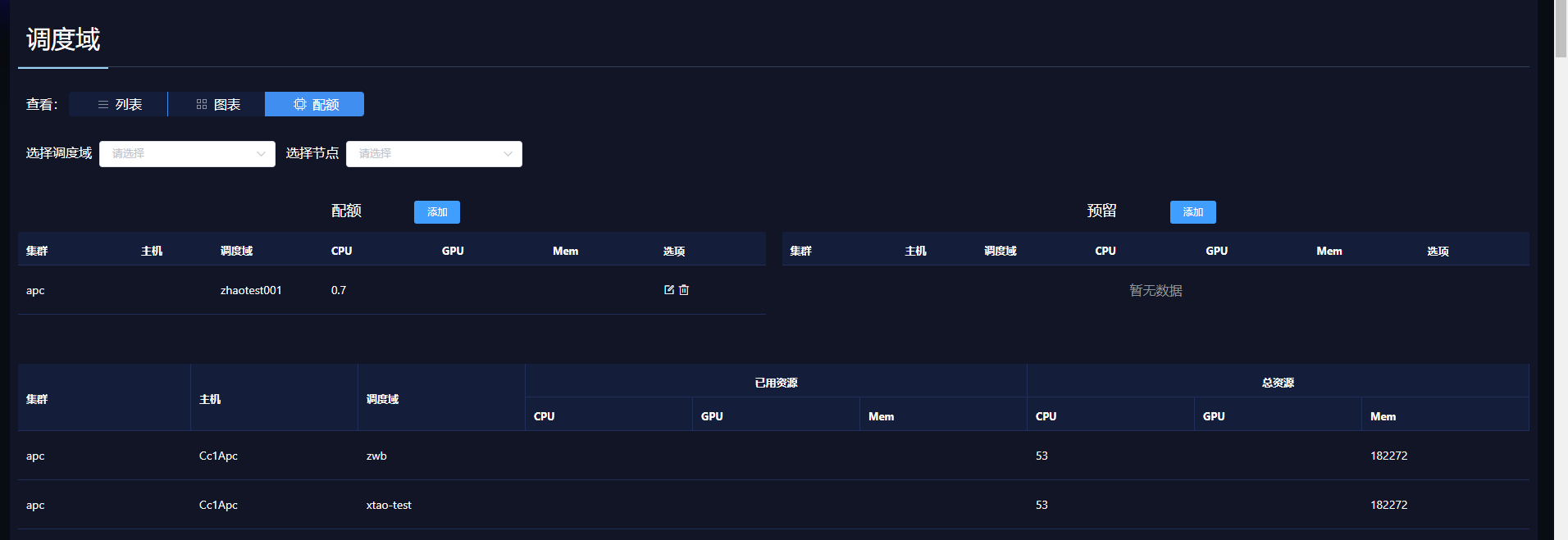
除了上述功能,管理员用户也可以进行资源预留。一旦资源被预留,这部分被预留的资源(CPU、内存等),不会被使用。
如果某个用户属于多个调度域,又需要任务投递到某个特定的调度域,则需要在job文件中指定。例如:
{
...
"ScheduleDomains" : "dom1"
...
}