疾病标志物与机器学习——初窥门径
随着医学数据不断地积累以及以二代测序、高通量质谱技术为代表的高通量分子检测手段应用的普及,为疾病标志物的发掘提供了数据基础。从目标来看,疾病标志发掘的目的是找到方便检测的疾病指标,来完成对疾病的早期诊断和分型以指导治疗,而从技术角度来看,其过程是找到潜在标志物与疾病之间的关联性。显然,医学发展到现阶段,容易发现的标志物已经都得到了很好的应用。而不容易的,则是传统技术手段难以发现的。这种过程正是以支持向量机(SVM)、随机森林、贝叶斯网络等机器学习技术的长项。
什么是疾病标志物?
在医学中,生物标志物是某种疾病状态严重程度或存在的可测量指标。更一般地,生物标志物是可以用作特定疾病状态或生物体的一些其他生理状态的指标的任何东西。根据世界卫生组织的说法,指标在本质上可能是化学的、物理的或生物的——测量可能是功能的、生理的、生化的、细胞的或分子的。
例如,当我们体检时,空腹抽血的主要目的是测量肝脏功能的几个重要指标,俗称两对半,如果谷丙转氨酶指标过高,有可能体检者就需要关注一下自己的肝脏了,比如是否携带乙肝病毒、饮酒过量(现在最大的可能就是腹型肥胖)
因此,我们疾病标志物应该具有:
- 有效性 标志物可以确实的反应实际情况。
- 可检测且检测简易 指标是可以被现有技术检测到的。比如疫情期间,咽拭子试剂盒之所以被广泛应用,还是得益于检测的方便,不然很难想象,只通过胸透片子如何完成多座城市的普查。
- 具有一定的前瞻性 在疾病发生前给出预警,或预后恢复情况。
- 可比较性 给出一定的指导标准,超过或低于这个标准,则表示疾病的风险。
如何发现标志物
传统意义上,标志物的发现需要首先对疾病的分子机制有一个相对明确的认知,例如如果需要要救阿尔兹海默症的标志物,就首先需要绘制下面这张图
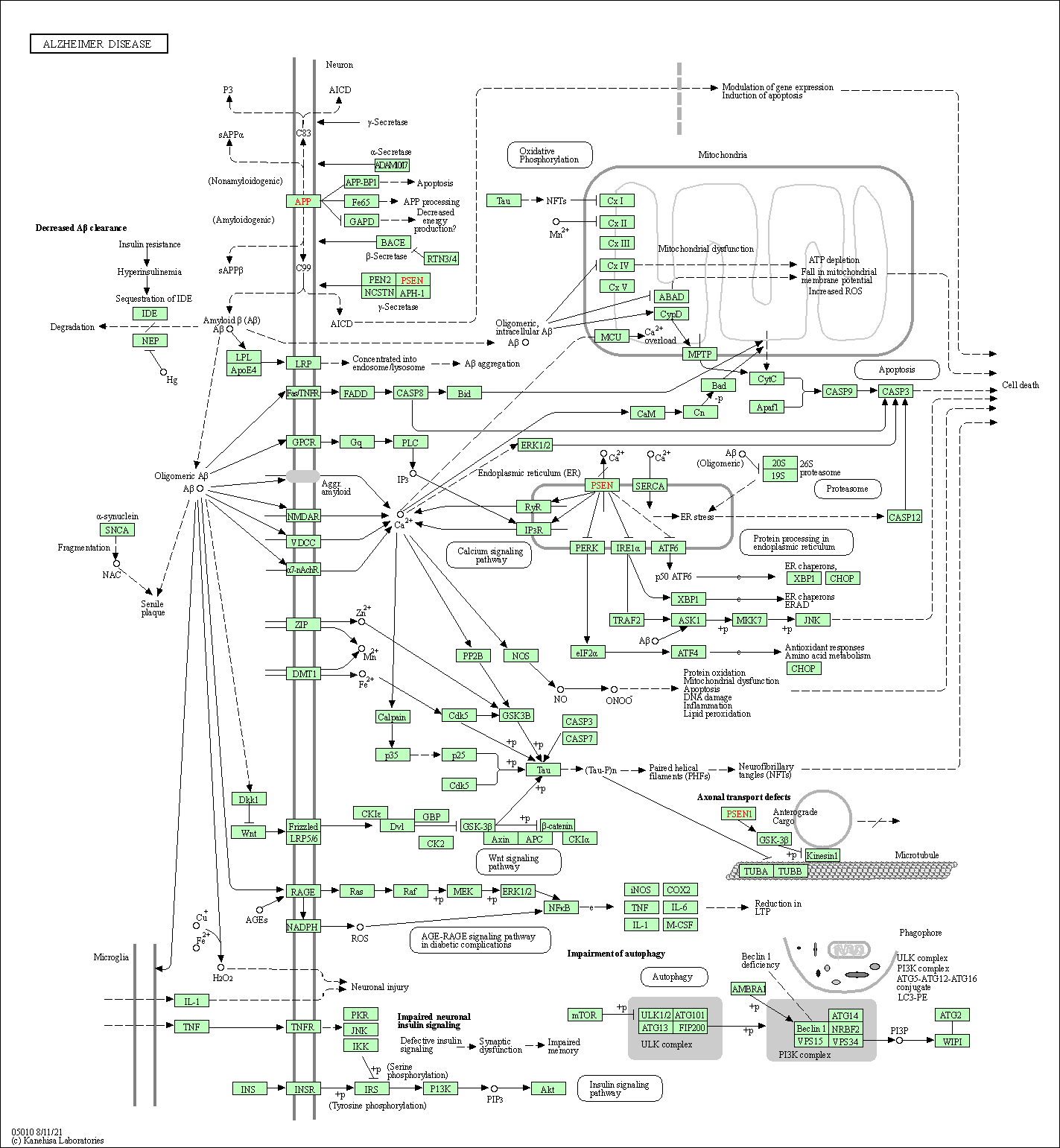
再通过分析推断出通路中某个环节会存在异常,致使某一步生化反应无法正常进行或收到抑制。从而反到某个代谢产物量或者修饰的异常。此过程中,将确定多个候选分子,每个候选分子都需要经过验证才能进入临床研究。这涉及检测开发——要求检测对监测特定候选生物标志物具有敏感性和选择性。
总之,生物标志物开发的步骤包括:生物标志物发现、检测开发和验证、临床效用验证和临床实施。生物标志物的发现和开发是一个漫长的过程,需要假设生成、样本收集、数据收集、数据分析、检测开发、检测验证和最终监管批准,然后才能用于临床。
标志物研究存在的几个问题
1. 疾病的分子机制尚不明确
例如最热门的疾病癌症,其发病基础很难用一个通路完整概括,例如阿尔兹海默症,现在虽然有多种假说及支持证据,但是没有定论的疾病,就很难用传统的通路分析方法筛选出有效的标志物。
2. 标志物不见得直接参与疾病过程
标志物虽然可以反应疾病进程,但是标志物本身不见得参与疾病的分子过程,这就造成了传统的通过代谢通路去挖掘标志物的方式具有一定的局限性。尤其是对于目前很多病症而言,科学家并不能完全解释疾病发生的机制,因此传统的标志物研究方法不一定能
通过机器学习方法获得疾病标志物
机器学习这个名词虽然在近些年广泛地出现在各种场合,让人有一种错误认知,即机器学习高不可攀,事实上,所谓机器学习只是一类方法,其最大地特点是通过过往海量数据加上特定的算法,获得一系列用传统方式难以获得的结论。
疾病标志物的挖掘为例,自从随着测序技术为代表的高通量检测手段井喷式发展,目前各个科研机构和医药企业,手中都积累了海量的数据。这些检测数据,配合上医疗机构的临床表型数据,恰好是疾病标志物发掘的“金矿”。
机器学习应用疾病标志物发掘面临的问题
另一方面,海量数据的问题又在于仅靠关联分析或传统的回归分析,在准确性方面往往存在较大缺陷。这主要是由于和传统方法相比,高通量检测手段的数据结构往往是一个样本对应非常多的指标,而样本数相对指标数而言非常有限。从而造成过拟合问题。虽然这个问题的在很大程度上其实受限于数据量,但是总的来说,由于在生物信息学中指标数量一般都远远大于样本数量,因此过拟合的问题其实比较难以解决。
另一方面,由于人类的多样性,很多疾病包含了人种因素、生活习惯因素等等,随之而来的变量组合数量也会变得非常巨大,对计算消耗量也非常惊人。因此对如何使用好算力也是应用机器学习方法进行疾病标志物发掘的一个重要问题。