计算云——面向计算优化的云方案
无论是基于虚拟化的公有云还是基于容器的容器云(例如架在公有云上的k8s),都不是天然为HPC或者计算类业务优化的基础架构。那么“云”和“计算”理想的结合是什么呢?笔者认为应该是计算云。大家如果认为笔者前两篇文章是在挑刺的话,那这篇文章就尝试开个药方。
计算云是什么?
笔者所谓的计算云指的是为计算业务优化的类云基础架构,它强调用云的方式解决计算问题,而不是将“计算”搬到现有的公有云或者容器云上。目前公有云或者容器云(例如k8s)上的HPC解决方案本质上都是将现有的HPC方案虚拟化或容器化,以虚拟机或容器替代物理机。这些做法是为了将公有云资源卖给计算用户,并没有改进计算业务本身。
从用户的角度说,计算云是什么样的呢?笔者认为计算云应该具备下面几个特征。
1. 计算即服务
计算云提供的应该是端到端的计算服务,而不是资源服务。以一个传统环境下的HPC用户举例。HPC集群各个计算节点挂载了分布式文件系统,用户(或者系统管理员)将计算程序安装到分布式文件系统。用户登录到集群的登录节点,通过qsub投递一个单机计算任务,或者通过mpiexec提交一个MPI计算任务。调度系统(例如SGE、PBS、Slurm等)分配合适的计算资源,完成用户的计算任务。如果把HPC集群搬到云上或者容器里,使用方式仍然类似。系统管理员拉起一个HPC集群,普通用户登录集群使用计算服务。
现在问题来了。如果这个用户需要混合使用MPI、Hadoop、Tensorflow怎么办呢?系统管理员需要拉起三套集群,分别做三种计算。用户需要登录到三套不同的系统中提交任务。这三套系统的使用频率、负载程度不一样,系统管理员不可能实时动态管理集群来确保资源利用率。系统管理员以容器云的方式将HPC集群容器化是一种计划经济,没有市场经济的效率。计算应该由用户主导,按需分配。按需分配意味着程序化自动调度。基于k8s的Volcano解决问题的方式是让普通用户使用k8s模版提交任务。MPI用户需要提交服务模版去启动一组运行sshd服务的容器,然后启动一个运行mpiexec程序的容器。这种方式将系统管理员的工作转移到了用户身上,用户需要学习使用k8s。用户真正关心的是他自己的MPI程序,不是k8s,也不是运行sshd容器。造成这个问题的原因是k8s只是一个PaaS解决方案,本质上提供的是资源服务,不是计算服务。
真正的计算即服务要求用户不需要做与自己计算无关的事情。计算集群提供一些登录容器或者服务器,用户登录服务器安装软件到分布式文件系统,或者将软件打包成容器。用户根据自己的需要在登录节点通过qsub或者mpiexec提交作业,指明作业需要的资源和数据。计算云根据任务的类型,按需分配资源,构建HPC、Hadoop或者Tensorflow集群完成计算。计算过程中的资源如何分配,集群如何部署和销毁,数据如何共享是计算云内置的服务,不应该有用户参与。用户只需提交数据和程序到计算云,然后等待计算结果。

2. 按需共享资源
“云”的方式意味着资源的集中和共享。随着技术发展,计算早已经从计算密集型的科学计算,演化到数据密集型的数据加工,或者两者并重。与计算类型的演化对应,计算框架和编程模型随之发展。从最原始的MPI全靠自己写代码,到Hadoop和Spark的Map-Reduce编程模型,再到Pregel方式的图计算,近年又流行Tensorflow和PyTorch等机器学习框架。计算模型和框架越来越多,谁都想一统天下,但谁都不可能一统天下。计算框架的多样化是计算发展的必然结果。因此计算云需要让多种不同的框架共享硬件,确保资源利用率。
无论是虚拟化的公有云还是容器云,都能做到不同的计算框架静态共享物理硬件资源。SGE、PBS或者SLURM是传统的HPC的调度系统,将它们做成虚拟机部署到公有云,或者做成容器部署到k8s,可以让多种框架共享物理硬件。但是这种共享是静态的。典型的使用方式是:1)系统管理员在云上或者k8s上拉起一个SLURM集群。2)用户通过SSH登录到集群,使用传统的方式安装软件、投递任务。这种使用方式得到的好处是什么呢?一是不需要为每个集群单独购买硬件,二是系统管理员的集群部署工作得到了简化。其它方面没有改进。
我们所说的按需共享指的是什么呢?是不同的计算框架按照计算负载的需要实时从系统中分配资源进行计算,计算完毕后归还资源。没有静态的SGE容器集群,也没有静态的Tensorflow集群。静态的容器集群意味着资源不是按需共享的,因为计算负载是实时变化的,系统管理员或者工具不可能动态操纵计算去匹配这种实时变化。
静态共享的方式下,管理员仍然处于中心地位,按需共享的方式则要求最终用户处于中心地位。系统管理员处于中心的应用方式下,用户的需求通过和系统管理员的神仙打架来解决。按需共享要求程序化满足用户需求,即系统管理员配置调度策略,最终用户提交计算任务,其它一切都由系统自动完成。
3. 跨框架计算
跨框架计算在多框架共享硬件基础上再前进了一步。共享解决了资源利用率的问题,跨框架计算使得用户可以自由组合多种不同的计算框架解决一个复杂的业务问题。举一个简单的例子,用户有大量数据,需要先进行数据清洗,做ETL转换,然后进行机器学习,最后的模型用于预测另一批数据。这是一个简单的AI应用场景。用户选择用Spark处理数据,用Tensorflow机器学习,这就是一个跨框架的计算业务。传统的解决方法是用户自己搭建一个Spark集群和Tensorflow集群,通过程序或者脚本组合API实现清洗、训练到预测的业务流程。如果另一个用户也需要做类似的事情呢?如果机器学习选用PyTorch呢?如果流程的参数有不同呢?笔者造访了一些大的自动驾驶公司,做数据平台和训练平台的动辄两三百人,可谓“有多少人工就有多少智能”。不是每个企业都可以投入这么多人力的。那有没有方法可以用搭积木的方式自动帮助用户构建复杂的数据处理业务呢?笔者认为就是跨框架计算。
跨框架计算能够很好的解决上述问题。跨框架计算在系统层面动态调度框架,不但解决资源问题,还解决数据的流动问题。用户定义一个Pipeline,由多个stage组成。第一步是运行一个任务调用Spark清洗数据,结果输入到Tensorflow程序进行分布式机器学习,输出的模型用于预测指定的数据。这个Pipeline类似于传统的程序,只是规模更大。与传统的C++、Java程序不同,这个程序的指令是单个容器或者框架,内存是各种存储介质,输入输出是存储中的海量数据。用户只需要将自己的程序封装成容器,定义成Task,然后将Task串联成Pipeline。Task之间可以定义参数和数据的输入输出关系,形成数据流。程序的执行引擎类似于虚拟机,自动解析Task输入输出的依赖关系,生成执行计划,最大化并行效率,并根据Task的需求自动构建或者销毁Spark或Tensorflow集群,向用户隐藏所有的框架部署和执行细节。听了这个描述,大家是不是有一种 “力拔山兮气盖世,天当被子地当床 ” 的赶脚?有人可能会说:你这有点放飞自我,吹牛呢吧?还真不是这样。跨框架计算只是极道的Achelous提供的诸多功能的一种。
4. 智能运维
调度程序化的自然要求是运维智能化。动态实时共享资源和跨框架计算要求系统管理员从系统中消失,调度和部署由程序承担,对应的运维也必须由程序完成。因为产生问题的速度增加了,解决问题的速度也必须相应增加,不然系统就运行不下去了。
有过大型系统运维经验的同志都知道,HPC类的大规模计算系统倾向于将系统资源用到极限。在极限情况下,硬件、存储、网络、操作系统呈现出各种异常、扭曲和变态。笔者服务过的很多生命科学计算的客户,他们的生物信息工程师写出来的程序可谓无所不用其极。创建百层目录,每个目录下产生千万级文件是家常便饭。还遇到过运行的命令行的参数大小超过了操作系统的限制(128M)。所有这些以前需要专业的技术人员分析、诊断和解决的问题,对计算云来说,都需要通过程序智能分析,自动恢复。
典型的计算云是什么样的?
大家看到这里,可能会说:“你在这里胡吹,具体计算云是什么样的呢?是骡子是马,拉出来遛遛”。笔者在这里兜售一下私货,向大家介绍一下极道的Achelous。Achelous作为一个智能数据系统,也可以作为计算云的解决方案。
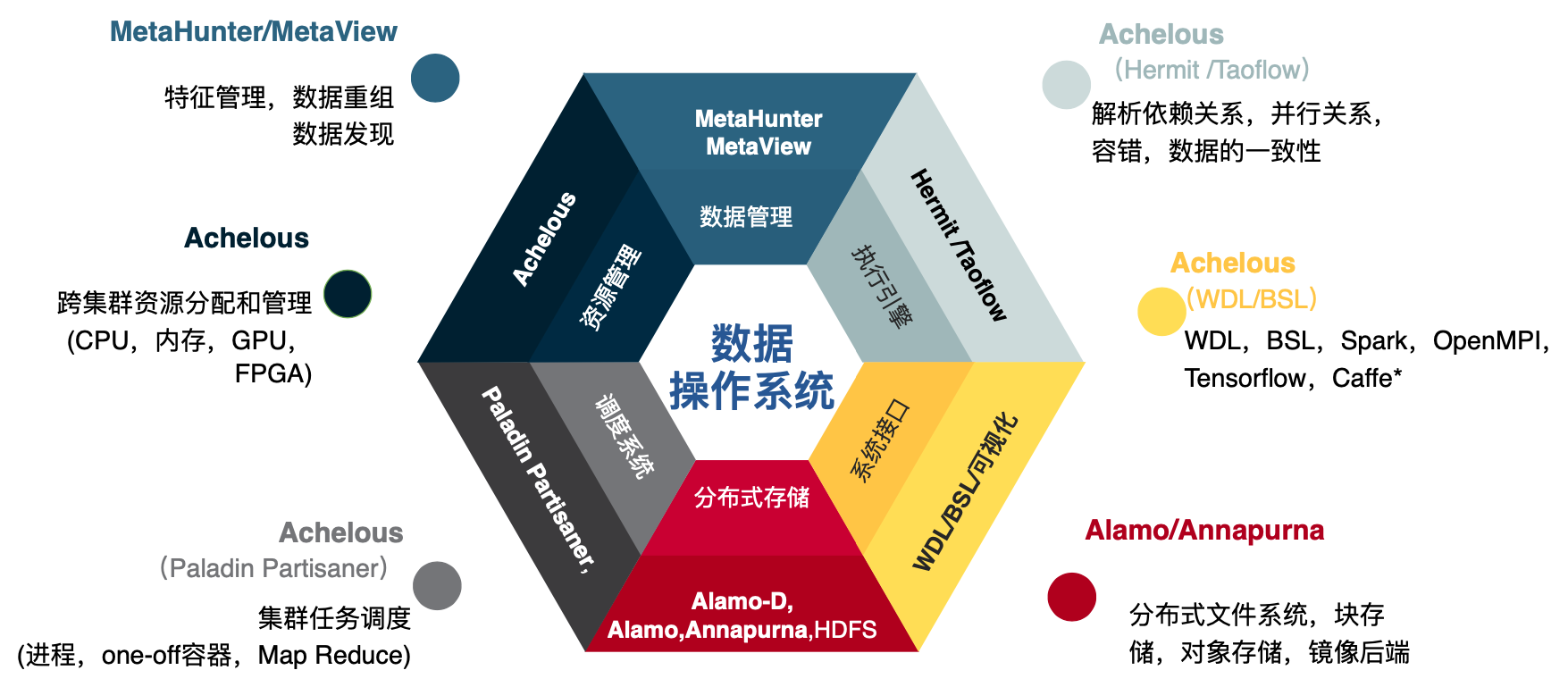
容器化
容器化技术可以帮助解耦硬件和执行环境,将框架打包成容器使得框架可以在任何机器上运行或者迁移。Achelous支持Docker和Singularity容器化技术,也支持直接将二进制程序运行在操作系统上,支持传统HPC用户的无缝迁移。
集群资源管理
Achelous的SRM服务将系统中所有物理机器的所有硬件资源组成资源池,支持但不限于CPU、Memory、GPU、FPGA等等。SRM接受各个应用框架的资源分配/释放请求,并负责监控和管理任务状态。Achelous通过灵活丰富的分配策略和算法在这个层面解决了异构资源调度的问题。社区的k8s,Mesos,或者yarn都在某种程度上提供这个层面的功能。
调度器
调度系统匹配任务和资源,支持灵活的调度策略和错误处理机制。Achelous实现了多种类型的调度器,支持多种不同类型的框架。Paladin调度一次性容器(类似于SGE),Partisaner调度一组容器(用于支持MPI、Tensorflow等等)。基于容器的调度器是跨框架计算的基础组件。
现有的计算平台(例如k8s,volcano等等)一般都可以支持到调度这个层面。这个层面解决了计算资源、调度策略和管理策略的问题,只能算实现了容器化。从用户角度来说,也是不完全的容器化。例如在k8s上运行一个SGE或者Slurm集群,只是将SGE或Slurm容器化了,并没有将用户程序容器化。
从下面开始步入了计算云的核心功能。
存储调度
企业计算系统需要访问各种各样的存储,包括各种分布式文件系统、分布式块存储和对象存储。不同的应用对存储介质和访问协议的要求不一样,对数据访问一致性要求也各不相同。计算云不但要调度资源,还需要调度数据。存储调度的核心功能在于为特定应用程序匹配最优的存储和IO策略,并打通应用之间的数据流。例如用户数据存储在POSIX接口的分布式文件系统中,数据清洗需要使用Spark,结果需要作为CSV文件进入高性能存储介质,作为机器学习训练的输入。Achelous存储调度根据应用Task的特点自动选择合适的存储,自动确保下一个阶段执行时数据在合适的位置,无需用户干预。
存储调度依赖计算系统和存储系统之间的协同设计。例如Achelous的数据流执行引擎,支持用户描述任务IO特点,自动帮助应用优化IO访问,提升计算性能。
DSL和执行引擎
对用户来说,企业级计算系统的两大痛点是编程和运维。集群资源管理和调度通常只能解决资源分配的问题。很多领域的编程语言(DSL,Domain Specific Language)尝试解决用户编程问题,但是并没有与调度系统实现有效的配合。在应用、调度系统和存储之间普遍存在语义鸿沟(Semantic Gap)。应用、调度和存储相互割裂,拼凑在一起的解决方案并不能有效解决用户的计算问题。虚拟化(OpenStack)和容器云(k8s)等解决方案直接将其虚拟化或容器化,改变的只是运行环境,计算没有本质提升。
Achelous实现了两种DSL(BSL和WDL),通过特有的runtime特性,打通了应用、调度和存储之间的边界。它自动解析任务之间的数据依赖,确保最大并行效率;根据应用类型,自动构建和销毁框架,实现实时动态资源共享;根据应用IO特点,自动优化数据访问,解决关键应用性能。它不需要用户重新编程,即可获得计算云带来的红利。
智能运维:
Achelous的AIOPS系统支持无人运维,自动故障检测和恢复。从C++和Java程序猿的观点来看,它是DSL数据流应用的Try and Catch机制。从此运维人员只需要配置策略,不再需要和用户通过神仙打架的方式解决日常系统运行问题。
小结
云计算是一个非常大的概念,但对于规模计算而言,真正可以基于云计算平台解决方案屈指可数。Achelous 系统是容器化、集群管理、任务调度、存储调度、执行引擎和智能运维的有机结合,是生命科学、地理空间、科学计算、人工智能等数据密集型和计算密集型领域最为全面的解决方案。