数据和计算系统如何容错?
容错是大规模数据系统和计算系统的必备功能,不能容错的分布式系统基本没有可用性。大家可能觉得高质量的系统错误率没有那么高,实质上系统的故障率总是随着系统规模和复杂程度增加。笔者读书的时候曾经听过一位参与过先进飞行控制系统设计的专家讲课。这位专家有一句原话是说飞机大多是带故障飞行的。笔者很多研究无人机的师兄们都有意无意的避免坐飞机。笔者坐飞机也会再三确认购买保险 :) 这不是吓唬大家,只是为了说明容错与我们息息相关。本篇我们来聊聊系统容错的方方面面。
1. 可靠性从哪里来?
1.1 安全、可靠与可用
安全(safety)、可靠(reliable)和可用(available)是我们常用的几个词汇。安全通常指避免灾难的能力,可靠指的是无故障提供指定功能的能力,可用指的是某个时间段系统能够正常运行。安全与可靠容易区分。举个例子来说,一架飞机坏了停在地上,它是安全的,因为它不可能引发灾难,但是不可靠,因为它无法完成飞行任务。可靠和可用的区别是什么呢?再举一个例子,你把钱存在银行里,晚上银行下班了,你没法通过柜台取钱。你的资产没有问题,银行具备可靠的保管你的资产的能力,但是它的服务不是7 x 24 小时可用的。
存储行当的人常说的黑话有DU(Data Unavailable)和DL(Data Loss),DL指的是数据丢失,DU指的是数据不可用。例如一个存储阵列的机头坏了,数据仍然在硬盘里,但是访问不了,这就是DU。如果一个RAID5,硬盘同时坏掉了二块,数据丢了,那就是DL。保证数据可靠可用是数据系统的生命线,在这个基础上谈性能和功能才有意义。
1.2 失效安全是第一原则
系统设计应该将失效安全确定为第一原则,它指的是如果我们的系统发生故障,应该尽量避免灾难性的后果。典型的例子是电梯故障后第一时间停止不动。数据系统中常常需要去重(deduplication),如何高效的找到重复数据呢?常用的方式是计算数据的指纹,例如数据的MD5哈希值。如果哈希值不同,则认为数据不一致,如果哈希值相同,则直接比较数据确认数据本身一模一样。哈希算法原理上不能排除不同数据有同样的哈希值,但是同样的数据必定有同样的哈希值,所以用哈希值可以过滤掉不同的数据,直接比较原始数据才能确认完全的一致性。这个方法体现了失效安全的设计原则,因为哈希重复的小概率事件不会导致不同的数据被误判成相同而造成数据丢失。
1.3 可靠性从哪里来?
任何系统,无论硬件或软件,都可能存在故障。构成系统的组件越多,系统组件故障概率越高。如何在存在故障情况下仍然保证复杂系统的可靠性和可用性呢?答案是容错,即在系统层面屏蔽组件故障。一切容错方法的基础是冗余,即存在多个组件执行同样的功能。例如数据在多个硬盘上做RAID需要硬盘空间的冗余,服务在多台机器上做热备需要额外的机器做冗余。冗余转化为成本的增加,容错方法增加了系统无故障时的运行代价,必然带来一定的性能损耗。所有的系统设计最后都面临可靠性、性能和成本之间的权衡。我们常听到某些厂商的宣传,说他的系统性能达到物理极限,可靠性达到了几十个九,但是价格非常便宜。从原理上讲这中间可能有一项是在打消费者的马虎眼。可靠性是设计出来的,不是吹出来的。
1.4 容错总有个限度
冗余是可靠性的基础,那么冗余决定着系统对错误容忍的限度。用户成本总是有限的,不可能配置无限制的冗余,所以不存在无限制的容错。例如数据存三分拷贝,那么只能同时容忍三个硬盘故障。那么限度之外的可靠性怎么保证呢?靠管理。拿存储系统来说,必须有人定期巡检,监控硬盘的健康,故障硬盘及时更换,老化的硬盘主动替换。它的目的在于减少故障的概率,延长一次故障和二次故障之间的时间。实际中很多客户或者集成商,硬盘坏了不知道,或者拖延处理,结果造成冗余耗尽,数据丢失,故障演变成灾难。
笔者曾经在某研究所实施系统,实施过程中布线需要拆掉半层楼的地板。某位老师过来帮忙,不小心把旁边友商的电源踢掉了,造成服务不可用,恢复了半天之久。友商系统采用的是三个数据拷贝的冗余,但是因为电源不够,三台机器都连接在同一个电源上,最终造成了一个单点故障。所以说再好的技术也不能弥补管理的漏洞。可靠性是技术和管理相辅相成的结果。

2. 所有的系统都是分布式系统
计算机系统发展到今天,大量采用了分层设计的观念。下层为上层提供服务,上层把下层系统当成一个黑盒子,只关注功能接口,忽略实现细节。分层设计的优势是不同层次的人可以独立工作。分层设计的性能不是最优的。为了提升性能,需要打开黑盒子,给上层提供更多额外的语义,将内部实现机制暴露出来,即所谓协同设计。例如操作系统开发者常常要处理刷TLB缓存,操作memory bar,关注内存顺序模型(memory model)等等。因为计算机硬件的多CPU、多核、内存和外设之间也存在复杂的交互协议,事实上构成了一个分布式系统。为了提升性能,一个CPU指令写内存时,如果内存被别的CPU锁住,它可能选择将写操作缓存到硬件buffer中,异步刷到内存。如果另一个CPU要读同一个内存的内容,这个时候要求程序员调用硬件的某个机制确保刚才的更新操作从buffer到了内存。
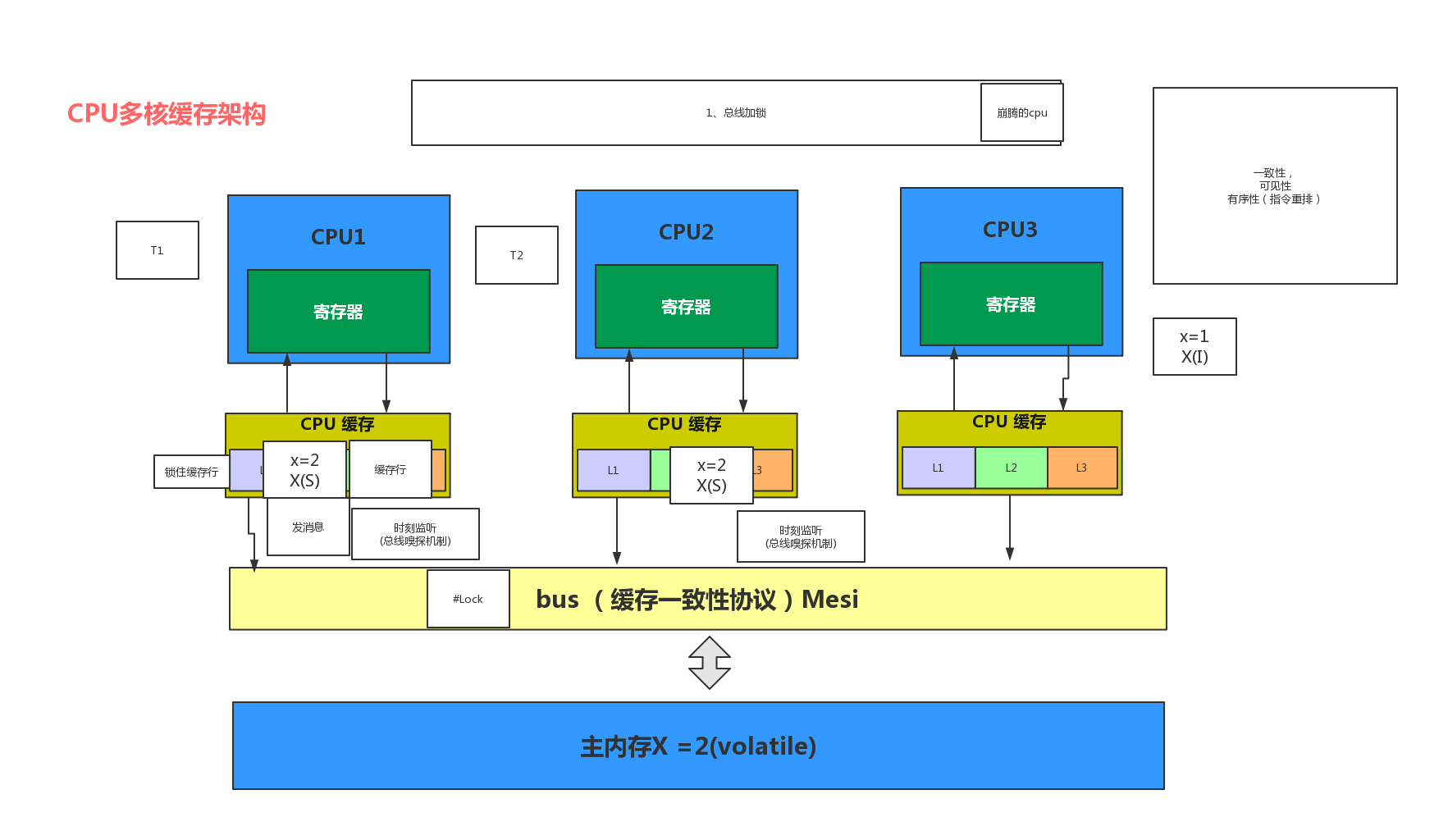
上图展示了多CPU和内存在微观层面运行一个MESI协议确保缓存一致性。下图的硬件系统运行的则是更高级和复杂的基于Directory的缓存一致性协议。这些协议并不比一个典型的分布式数据系统使用的算法简单,却在在一个访存指令中完成。软件与硬件并没有特别严格的界限,软中有硬,硬中有软,软硬兼施才是王道。
很多人将存储系统也理解成硬件盒子。事实上即便是最传统的存储系统也是由硬件和软件组成的分布式系统。这其中包括多个主机、硬件柜(JBOD)、多硬盘,且不说主机上运行复杂的存储软件,即便是JBOD和硬盘都不是纯粹的硬件,上面也运行固件(firmware),和存储软件发生复杂的交互行为。可靠性设计正是要从这个分布式系统出发考虑,通过硬件之间的冗余,传输线之间的冗余,JBOD之间的冗余,控制器软件之间的交互,最后实现一个黑盒子的整体可靠性。即便是个黑盒子,它仍然会输出某些接口给使用者,在上层应用的配合下,达到性能和可靠性的权衡。文件存储对外提供的sync语义就是一个很好的例子。如果没有sync语义,所有的写操作都要落盘后返回,性能损耗非常大。由调用者决定数据的落盘时间,实际上将确保数据可靠性的部分责任交给了用户,以换取更好的性能。
3. 传统数据系统的容错
传统的存储系统发明了很多容错方法,逐步演化成确保数据系统可靠和可用的常规手段。理解他们是理解系统容错的基础。
3.1 几种典型的容错设计
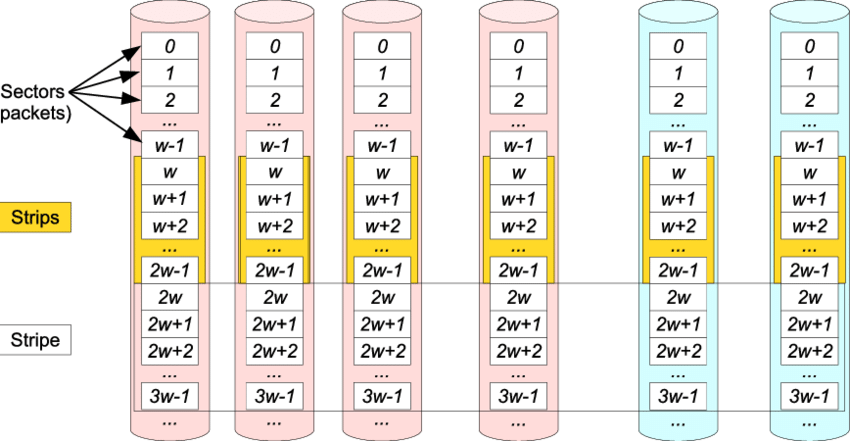
多副本应该是最早的数据容错方法,它将数据存成N份,并确保N份数据完全一致,这样可以容忍N-1份副本的丢失。它带来的问题是有效空间只有总空间的1/N,从成本上来讲很不划算。后来CMU的教授发明了RAID算法,包括RAID5、RAID6、RAID10等,使用户获得了空间利用率和可靠性上更多的选择。后来发展的纠删码Erasure Coding,还有说的很玄乎的网络编码,本质上都是编码方法不同。他们原理上都是数据分割成片段,把冗余数据块扩展、编码,并将其存储在不同的位置,比如磁盘、存储节点或者其它地理位置。没有绝对先进的编码方法,所有的方法只是根据需要在性能、可靠性和成本之间做权衡。
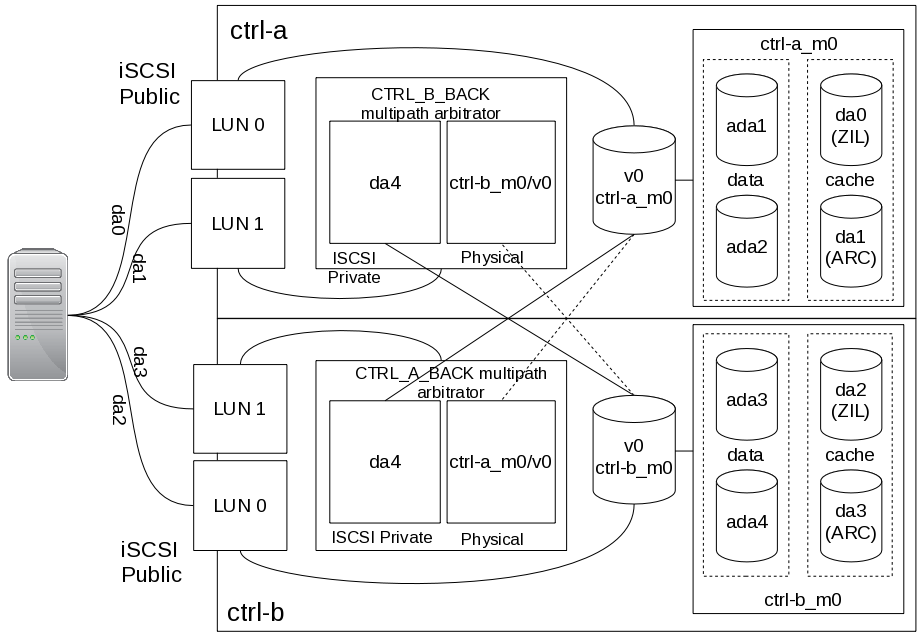
多副本和RAID编码解决了数据的可靠性问题,没有解决数据服务的可用性问题。传统存储系统有双控制器的设计方法,即两个机头带着一个硬盘JBOD,硬盘做RAID保证数据可靠性,控制器的软件互相热备保证服务可用性。如果两个控制器都可以同时提供同一份数据的访问,那就是所谓的双活active-active,否则就是热备active-passive。双控设计解决了可用性问题,但是引入了另外的难题。
3.2 双控是睡不醒的噩梦
在所有关于N冗余的问题中,N=2必定是最难的,因为需要两台机器在故障发生且没有第三方仲裁的情况下达成一致(回忆一下你和你老婆或者丈夫吵架的情景 :D)。所以双控制器的存储系统是最难实现的。双控系统的控制器在检测到对方故障的时候,需要接管数据服务。因此双控必须解决所谓的脑裂( split-brain)问题,即两个控制器都认为对方死了,尝试接管服务。双控系统的核心问题就是避免两台机器访问同一份数据,造成数据损坏。
双控系统的两个控制器之间通过心跳检测对方故障。然而不幸的是,网络故障和机器故障是无法区分的。控制器A认为B已经宕机,可能只是因为A、B之间的通信故障了,B控制器仍然在读写数据,所以A认为B故障即接管服务可能造成灾难。存储软件的一个重要任务是确保数据的受控访问,避免这种情况发生。解决问题的方法是增加更多独立的心跳。所以双控制器之间借助网络、PCIE、共享硬盘等所有可能的渠道,确定对方控制器是否真的宕机。通常从第一心跳开始检测,如果第N心跳都断了,第N+1心跳还活着,那意味着网络故障,机器没有故障。然而如果所有的心跳都断了,你再次被推上赌桌,被迫做出一个决定是否接管服务。这个时候就是风险所在。当然早期的系统带有一种特殊的硬件机制,控制器可以控制彼此的电源(ipmi),如果决定对方宕机了,可以直接重启对方控制器的电源,即所谓一枪爆头。如果B实质上没有宕机,只是所有心跳都断了,A、B可能同时做决定杀死对方,谁的枪快谁赢,也有可能同归于尽。无论哪种情况,最多只有一个控制器接管服务,所以最坏情况是DU,而不是DL。从这里我们可以发现分布式系统中的一个原则:故障究竟是什么并不重要,重要的是大家一致认为故障是什么。
笔者经历过各种各样的双控系统,有些厂商连第二心跳都没有听说过,就敢于承载用户的生产数据,典型的放飞自我。很多科研院所和超算中心采用的分布式文件系统是开源的Lustre系统。Lustre不通过多副本确保可靠性,它采用的是给对象服务(OST)做双控。Lustre通常采用ZFS文件系统作为单机存储后端,控制器接管的是一个存储池(storage pool)。一旦双控失效,整个池就会毁掉。极道曾经多次友情赞助用户们恢复这类数据丢失。非专业用户要在生产环境用好Lustre,首先要有技术储备,其次得保持好运气。
4. 分布式系统的容错
从传统存储系统到现代的分布式系统,硬件变强,规模变大,容错却变难了。分布式计算本质上是多个节点上运行的多个进程通过消息交换协作解决一个问题。在后续部分我们统一称呼物理机器为“节点”,机器上运行的目标程序为“服务”或者“进程”。由于故障的普遍存在,一个可用的分布式系统都需要在故障发生的情况下仍然完成计算任务。与单机计算不同,容错是分布式计算的标准配置。
4.1 书本上的理论有什么用?
分布式系统的容错有丰富的理论和算法。有人也许会问“理论有什么用?”。理论的用处在于确定系统设计的极限是什么,指导你进行系统设计。它可以帮助你一眼看穿对方在吹牛,或者告诉你牛应该吹到什么程度为止。我们常见到一些学术论文上证明一些简单的分布式算法的正确性,觉得多此一举。其实分布式算法的难点在于其故障情况下的正确性。多机交互的时候如果出现故障,加上分布式系统运行固有的异步性,会演化出异常复杂的行为,超出人的直觉。算法必须保证在任何允许行为下的正确性。这个允许指的是故障模型,即算法正确的假定前提。
故障情况下的算法正确性是很困难但是常被工程师们忽视的问题。Google工程师们请教Lamport,在Chubby中首次实现了PAXOS算法,是因为工程师们自己撸不出一个可以工作然后测试通过的算法吗?PAXOS是一个被理论证明正确的算法,以此为基础才能建立可靠的分布式系统。后来Stanford的大牛提出RAFT算法,实现成ETCD,其中一个目标是改进PAXOS的模块化程度和可理解性。这从一个侧面反映了分布式算法的复杂性。
4.2 我们的故障有多良性?
如果革命的首要问题是分清朋友和敌人,安全的首要问题是弄清楚攻击模型,那容错的首要问题是弄清楚故障模型。故障模型描述我们容忍什么样的故障,不容忍什么样的故障,也就是我们的算法假定的前提是什么。自从冯诺依曼将计算模型数学化之后,计算机算法本质上是数学的应用,所以任何计算机系统算法的正确性和效率都有一个前提。没有前提,无所不能的计算机算法只存在于我们的微信朋友圈。
最简单也是最良性的故障类型是停止故障(fail-stop),指的是目标机器、服务、进程或者某个子系统一旦故障即停止运行。在不考虑通信故障和延迟的情况下,它意味着心跳断等同于服务挂掉,在很大程度上可以简化故障处理。但是在实际运行场景中,只有少数几种情况例如操作系统内核崩溃(panic)、进程coredump等属于这种情况。很多高质量的程序会要求服务自己模拟这种故障行为,即一旦检测到状态异常即主动停止运行。例如监控ETCD进行选举的服务在无法连接ETCD的时候直接退出,可以避免其子系统在领导改选(Leader切换)的暧昧期干坏事。笔者以前在某世界存储巨头工作时,看到大量的代码检查状态不正确就主动panic掉。当时笔者想这么关键的系统为什么要死的这么草率?殊不知第一时间避免故障传递、演变成灾难才是一个负责任的做法。不成功则成仁,在良性的分布式系统中,程序自检和自杀体现了一种社会责任。
最恶性的故障是拜占庭故障,它指的是目标可以表现任意的行为,包括但不限于故障停止、发送错误消息、计算出错、状态任意变化等等。大家可能会说,计算机都是程序行为,会这么变态吗?笔者的经验告诉大家,实际中大多数都是拜占庭故障。只有你想不到的,没有程序干不出来的。不同意的同志们想想你解决一个bug有多难。在理论上常可以把拜占庭故障理解为系统的一个对手(adversary),也就是把这个故障定义为导致你的程序运行出错的那个故障。Dijkstra说过,你永远无法证明你的程序是正确的。可见对手无处不在。
另一类重要的故障是通信故障(以下通信故障与网络故障交替使用,代表同样的含义)。网络故障的典型情况是消息丢失,这在实际中尤其是高负载场景下是普遍存在的。通信故障是很多难题在理论上无解的重要原因。通信故障常通过消息重传,或者重试来解决。有人可能会问:“我使用TCP协议不是足够解决通信故障了吗?” 答案是否。因为TCP协议只保证你的数据包可靠传输到对方的TCP缓存,不表示你的消息被对端的应用程序正确处理了。
4.3 我们的步调有多一致?
容错除了和故障模型有关外,还和系统同步(synchronous)或者异步(asynchronous)特性有关系。所谓异步,指的是系统各节点间运行速率差异和消息传输延迟没有上限,包括但是不限于消息传输可以任意慢,节点之间的时钟可以任意漂移。反之,系统就是同步的。我们经常采用的心跳超时来判断故障的机制只有在同步的系统中才有意义。对一个异步的系统采用超时机制,基本属于耍流氓,超时在任何情况下都可能发生,程序不能根据超时事件做出任何正确的判断,系统可能来回震荡,无法收敛。
那么实际中的系统是同步还是异步呢?笔者认为在计算密集型或者数据密集型的场景中,系统是异步或者半异步的。首先,由于网络丢包、负载不确定、系统资源很难做性能隔离(所谓的服务质量Qos保证),消息延迟变化范围很大。其次,最大延迟的上限可能存在,但是不能事先知道。这种情况就是程序猿们常常要调整的各种超时参数。第三,最大延迟最终可以确定,但是在性能上不能忍受,因为以此为基础的服务故障恢复时间不能满足业务需求。第二、三种情况就是所谓的半异步。
由于实际系统中大量依赖心跳超时检测故障,半异步也影响故障检测器的可靠程度。这个问题后续详细讨论。
4.4 费多大劲可以排个顺序?
分布式系统的一个重要问题是给系统中各个节点之间发生的事件排序。这里的顺序指的是所有节点一致认定的全局顺序。为什么要讨论这个问题呢?因为这在单机系统是一个简单问题,在分布式系统中(考虑故障)是个超级难题。单机系统中,多个事件可以通过互斥机制在小临界区串行或者分配序号获得全局顺序,虽然也是相对的效率瓶颈,但一般可以接受,也有很多优化选项。在分布式系统中,多台机器之间需要通过消息传递来确定事件的全局序,通信延迟造成的性能损失相对较大,而且分布式系统中的故障概率高,进一步加剧了问题的难度。
为什么要给事件排序呢?因为这和维护分布式系统各节点的数据副本状态一致常用方法状态机方法有关系。假设多个节点维护同一份数据的多个副本用于容错,如果系统能够确保所有关于该数据的操作以同样的顺序应用在所有副本上,那么副本的最终状态必然一致。有一点提请同志们注意的是,状态机方法保证的是最终一致性,它不能保证任意时刻各个副本状态是一致的。这是因为不同节点应用更新操作的延迟,以及操作耗费的执行时间都有差异。除非阻塞住后续操作,等待本次操作同步应用到所有副本,否则同时一致不再有意义。在分布式系统中,阻塞的代价非常大,所以一般都选择放弃同时。最终一致性的“最终”有没有时间上限呢?同步系统中,节点间的执行速率差异和消息延迟存在上限,因此各个副本达到同样状态的时间差异也有上限。在异步系统中,原则上不存在这个上限。
看到这里,有的同志会说,这个排序不是很简单吗?把所有操作发给一个节点(协调者),排序好后再发给其它节点不就可以了吗?是的,这是实际中可用的好办法。但是同志们别忘了,所有的分布式系统都是要容错的,因为只要规模足够大,或者时间足够长,故障是一定会发生的。首先排序的节点可能宕机。宕机是良性故障,稍微恶性一点的是协调者将排序结果发送给部分节点后挂掉了,即便选出新的协调者还需要进行一个恢复过程,重新同步副本状态。所以说问题难就难在各种故障发生的情况下仍然保证全局一致的顺序。这些故障包括但是不限于节点(拜占庭)故障、消息丢失(不同的节点收到不同的消息)、消息损坏等等。
闻名遐迩的PAXOS算法在实际中的一个直接应用就是在分布式系统中维护一个全局一致的日志(从而维护了一个多个副本但是全局最终一致的数据库),其本质就是决定这个日志的多个副本以什么顺序应用数据操作,即决定发生在不同节点的多个操作在日志中的顺序。这是一个典型的分布式事件的排序问题。
4.5 我们可能达成一致吗?
一致性问题(consensus)是分布式理论中最基础的问题。我们费点心思来看看它的定义。
系统中每个节点提出一个值,通过消息交互最终所有节点决定出同一个值,要求如下:
1. 所有正确的节点最终总能够决定一个值(termination)
2. 所有正确的节点决定的值必须相同(agreement)
3. 所有正确的节点决定的值必须是被正确的节点提出来的(validity)
看到这个定义,聪明的同志会说,这个也很简单啊,实现一个广播操作,负责给每个节点发送消息,确保所有正确的节点要么都收到某个消息要么都收不到某个消息,且所有正确节点发送的消息其它正确节点都会收到。这样每个节点把自己的提议值发给所以其它节点,最后所有节点收到的消息集合是一样的,用统一的规则计算这个消息集合必然得到同样的值。这位聪明的同志提出的这个广播操作叫做原子广播(atomic broadcast)。理论证明,原子广播和一致性问题是等价的。这句黑话的意思是说,你一旦有了consensus或者atomic broadcast其中任意一个问题的算法,简单处理就能够解决另一个问题。所以不要随随便便把难题甩给做基础服务的兄弟,它不一定能真正简化问题的解决。
关于一致性问题有很多理论结果。理论证明,允许通信故障的系统一致性问题无解。可见沟通有多重要:)。我们的Lamport(PAXOS算法的提出者,图灵奖获得者)先生证明了同步系统中,即便在拜占庭故障假设下,仍然存在一致性问题的算法,但是要求3N+1个节点最多只有N个节点故障。悲剧的事一致性问题在异步系统中无解。不存在证明的核心技巧与通信故障情况下类似,关键的观察是基于消息传递的系统中任意节点不可能在异步系统中区分一个无限慢的消息和一个丢失的消息。假定算法存在,而算法要求有限时间的终止,因此算法的正确性绝不能依赖这个消息。这样算法在每个节点都不能依赖每次执行情况下的最后一条消息。这是因为算法的执行历史对所有其它节点都一样,只对无限慢消息的接收者不一样。最后一步一步规约到算法的正确性不能依赖任意一条消息。这样与有效性要求(validity)矛盾。有效性要求本质上规定有效的算法必须基于正确节点的建议值,因此必须是沟通后的结果。沟通万岁!
上面这段很难理解的证明思路,说的是一个分布式系统中常见的问题,笔者称之为最后一条消息魔咒。如果假定网络不可靠,最后一条消息是否收到是无法被发送者确认的,即便消息并没有丢失。这意味着计算结果绝不能依赖最后一条消息的可靠性。一般的系统实现中,节点通过发送ack向发送者确认消息收到并处理了,如果网络不可靠,怎么知道接收者发送的ack是否丢失呢?我们看看下面的例子。

Bob和Alice约会之所以泡汤是因为在一个通信故障的假定下追求共识(common knowledge)。所谓共识,就是要建立如下的逻辑条件:
Bob知道 && Alice知道 && Bob知道“Alice知道” && Alice知道“Bob知道” &&
Bob知道“Alice知道Bob知道” && Alice知道“Bob知道Alice知道” ...
其中每一层次的知道对应于一个ack,所以要建立共识需要无限多次的ack。同志们需要注意的是这个例子中消息是否丢失并不重要,只要假定消息可能丢失,共识的正确性就要求无限多次确认,因此算法无法终止。那实际可行的约会方案是什么样的呢?
Bob告诉Alice:“晚上六点电影院见,不来请回复,我将等到六点半”。 # 请求
如果Alice愿意,就回复行,不愿意就回复不行。 # 反向确认 (Negative Ack)
Bob六点到达电影院,等到六点半,如果Alice不赴约就离开。 # 超时(Timeout), 解决Negative Ack丢失
这个方案中超时是算法终止的关键因素,反向确认(Negative Ack)只是优化性能(避免Bob傻等)。同志们现在可以理解TCP协议状态机中最后得有个Timed-Wait了吧,因为Ack的方法总得有个终止,最后必然依赖一个超时。
理论证明,在异步系统中,如果存在通信故障,consensus和common knowledge都不可能达成。同志们也许会问区块链为什么可以达成共识呢?区块链是基于零知识证明(zero knowledge proof)系统达成的近似共识,是概率性的。很多区块链方案中为了防止有人伪造全局账本,所有人必须不停的计算,避免有人拥有绝对算力,无论坏人是否存在。这是典型的内卷。
4.6 现实中如何达成一致?
既然理论证明,在异步系统中或者存在通信故障的场景下,不存在解决consensus问题的算法。但是一致性问题是一个必须解决的问题,那该怎么办呢?有些研究人员提出了基于故障检测器(failure detector)的方法。故障检测器作为系统中的一个模块,回答“这个节点或者进程有没有故障?”这类的问题。运行一致性算法的系统通过与故障检测器交互,最终达成一致。故障检测器被假定是不可靠的,即它可能犯错误。故障检测器通过下面的两个关键属性刻画:
完备性(completeness): 故障进程最终被检测为故障
准确性(Accuracy): 正确的进程不会被认为故障
这两个属性描述了故障检测器的犯错误的类型和程度。可以定义多种类型的完备性和精确性。故障检测器是一个理论工具,它可以帮助阐明在什么样的完备性和准确性条件下,系统可以达成一致,或者什么样的故障检测器有助于提高系统的一致性。如果有兴趣的同志研究一致性的算法,就会发现一致性的获得依赖没有故障的节点收集到一致的信息。换句话说,一致性来源于多轮次消息交换后各节点收集到的信息的一致性。如果故障检测器可以提升一致性,那一致性必然来源于故障检测器提供的某种一致性。例如:
弱准确性(weak accuracy): 存在一个正确的进程,从不会被其它正确的进程检测为故障
最终弱准确性(eventual weak accuracy):在足够长的时间之后,存在一个进程,不会被其它进程检测为故障
同志们一眼就可以看出,弱准确性或者最终弱准确性决定了系统(经过足够长的时间之后)可能找到一个可靠的进程作为协调者(coordinator)或者领导者(leader),算法可以依赖这个协调者达成一致。
故障检测器是一个理论工具,在实际系统中有很多对应。例如某些版本的PAXOS算法依赖选举一个Leader,但是不要求其唯一性,有些版本则不需要这个Leader存在。但是算法的成功终止(Termination)等价于存在一个协调者,不会被大多数参与者(Quorum)认为故障,以完成多数表决。否则,算法虽然不会给出不一致性的结果,但是会持续震荡,无法收敛。
4.7 CAP定理如何决定系统设计?
很多同志可能知道所谓的CAP定理,它由加州大学的计算机科学家Eric Brewer在1998年提出来:
分布式系统中,一致性(Consistency)、可用性(Availability)和分区容忍(Partition Tolerance)三个指标不可能同时达到。
一致性(C)和可用性(A)大家已经熟悉了,分区(Partition)指的是什么呢?举个例子来说明,系统中存在A、B、C、D和E五个节点,A、B、C互相可以通信,D和E互相可以通信,但是A、B、C和D、E互相无法通信,这种情况就叫网络分区(Network Partition)。如果分布式系统涉及到分离很远的两个站点或者数据中心,例如A、B和C在北京,D和E在纽约,那么分区问题是个常见情况。这个容易理解。即便在同一个数据中心内,分区也是很普遍的情况。我们在设计系统的时候,通常假定分区必然存在,因此必须在一致性和可用性上做权衡。CAP定理决定了在故障发生的时候我们可能需要牺牲其中一个指标以换取另个指标。不同的系统根据实际情况需要做出不同的选择。
存储和关键数据系统要求绝对的一致性,只能牺牲可用性。分布式存储系统牺牲可用性是什么意思呢?其实就是在一致性达成的过程中阻塞住客户端的操作,暂时把请求服务的程序Hang住。不好意思,我们再次回到了Hang这个问题:)。
当然也有系统做相反的选择。Amazon的S3明确说明不保证读写一致性。之前听Amazon的CTO的一个演讲,说他们的数据系统要保证总是可写(always writable)。为什么呢?因为客户要往购物车中放东西,你必须让他的操作成功,不能跟钱有仇啊。所以选择暂时牺牲一致性来获得可用性。当然某种程度的一致性是必须保证的,即所谓最终一致性。Amazon的很多系统采用客户端参与的冲突解决机制。例如A、B、C、D和E五个节点维护同一份数据拷贝,当A、B、C和D、E分区后,两个系统独立接受用户请求,当两个分区重新连接成为一个系统,需要恢复全局一致的状态,这个时候必须解决独立运行时的冲突操作。这个过程中可能需要应用系统参与解决冲突,选择一个最终的版本。这在很多场景下是合理的。例如你在购物的时候,不间断向购物车中添加或删除商品,这个时候数据是否一致是无关紧要的。只有当付款的那一刻,你才需要确认购物清单是什么。这个时候系统可以给出两种结果,由用户选择或者编辑。这就是客户端参与解决冲突的典型例子。
大多数系统倾向于保证一致性,因为强一致性对客户端更友好,更容易编程。最终一致性实质上是将某些确保一致性的职责交给客户端负责,以换取可用性或者性能。很多分布式系统采用所谓Quorum机制:
假设任意一个写操作必须完成的副本数为w,任意一个读操作必须读取的副本数为r,则 w + r > N
上述的Quorum条件w + r >= N实质上要求任意一个读和写操作必须至少有一个共同的副本,共同的副本承担了确保读写一致性的指责。至于怎么选择w和r取决于你的系统优化的是读还是写操作的可用性。假设你选择了w=1和r=N,意味着系统分区的时候任意分区都可以写,但是读操作需要从所有节点读取(其实就是要求读操作解决冲突)。
经典的PAXOS协议要求协调者必须获得多数(Majority)投票,否则不能达成一致。多数投票决定了任意两次协议运行之间必然有一个公共节点,确保前后表决的一致性。这意味着如果故障检测机制不能在某一刻形成一个正确多数,则一致性永远不能达成,协议无法终止,即失去可用性。因为PAXOS协议的目的是获得一致性,这个选择是顺理成章的。
4.8 直接民主还是民主集中?
实际中在构建分布式系统的时候,开发者可以选择诸如PAXOS、RAFT或者其它算法实现一致性。实现的时候通常有两种选择:无中心节点(decentralized)的方案或者ensemble的方案。前者类似于政治生活中的直接民主,后者则相当于民主集中制度。
无中心节点的方案要求每个节点都参与一致性协议。它的好处是不依赖于任何节点的可用性,缺点是代价较大,每一次都需要超过半数的节点投票。当系统规模变大,系统故障变多,协议运行的代价变得难于接受。所谓ensemble方案指的是首先采用一致性算法解决一个小团体(ensemble)的一致性问题,这个ensemble维护多副本数据,对外提供同步服务(例如分布式锁、原子性的检查设置compare-and-swap等),帮助其它服务达成一致。Google三件套中的Chubby,Hadoop系列的Zookeeper,以及后来的ETCD服务都是采用了类似的设计思想。
基于ensemble的方案是一个折衷,它既避免了单点故障,又以较小的代价实现了一致性,且简化了一般分布式系统的开发人员的工作。它为整个系统提供了一致性的根。一种常见的多副本运行方式是所谓的领导者-跟随者模式(leader-follower)。其中数据的多个副本通过ensemble选举出一个leader,其它的则为follower。leader对外提供读写服务,并将更新传递给其它的follower,follower同步状态,与leader保持一致。如果检测到leader故障,所有副本再次通过选举产生新的leader提供服务。
结束语
容错性是数据系统和计算系统非常重要的功能特性,它是系统开发区别于应用开发的一个显著方面。我们常说二八原则,即百分之二十的精力通常可以完成系统百分之八十的功能,剩下的百分之二十的功能往往需要百分之八十的精力。笔者认为容错性绝对在剩下的百分之二十的范畴内。它耗费的可不单是开发者的精力,也包括他们的健康。