Metis平台使用:从特征选择到模型建立
生物信息学的发展除了受益于高通量实验设备之外,计算能力的不断提升和新的算法的应用也功不可没。就目前阶段而言,机器学习技术已经在生物信息学领域得到了越来越多的应用。但机器学习需要的技术门槛相对较高,尤其是对于第一次解除相关领域的广大临床和科研用户而言,想要通过手中已有数据,构建一个简单的机器学习模型,往往需要从头学习一遍Python或R等编程语言。
鉴于此,极道科技针对机器学习的需求,开发了Metis平台,以满足用户的使用需要。对于基础用户而言,可以通过Metis的应用界面可以轻松完成数据可视化、特征筛选、模型构建与分布式部署、分析流搭建等操作。对于高级用户而言,也可以通过Python 客户端调用相关功能,加速分析效率。
下面就通过一个生物信息学实际应用实例为读者介绍Metis平台的使用方式。
1. 背景概述
1.1 TCGA 项目
乳腺癌作为女性高发癌种之一,在近年来的其发病机制、标志物发掘、治疗手段等各方面研究,已经取得了很大进展。癌症基因组图谱计划(The Cancer Genome Atlas :TCGA),也相应的披露了,针对乳腺癌的不同类型测序数据,以及相关临床信息、治疗信息等。该项目起始于2006年,其数据的质量和数据的完整程度,已经受到了癌症研究领域的广泛认可。
1.2 Metis 平台
Metis平台是由极道科技开发的,分布式机器学习计算平台。用户可以通过该平台轻松实现数据可视化、数据筛选、模型构建、分析流搭建等操作。
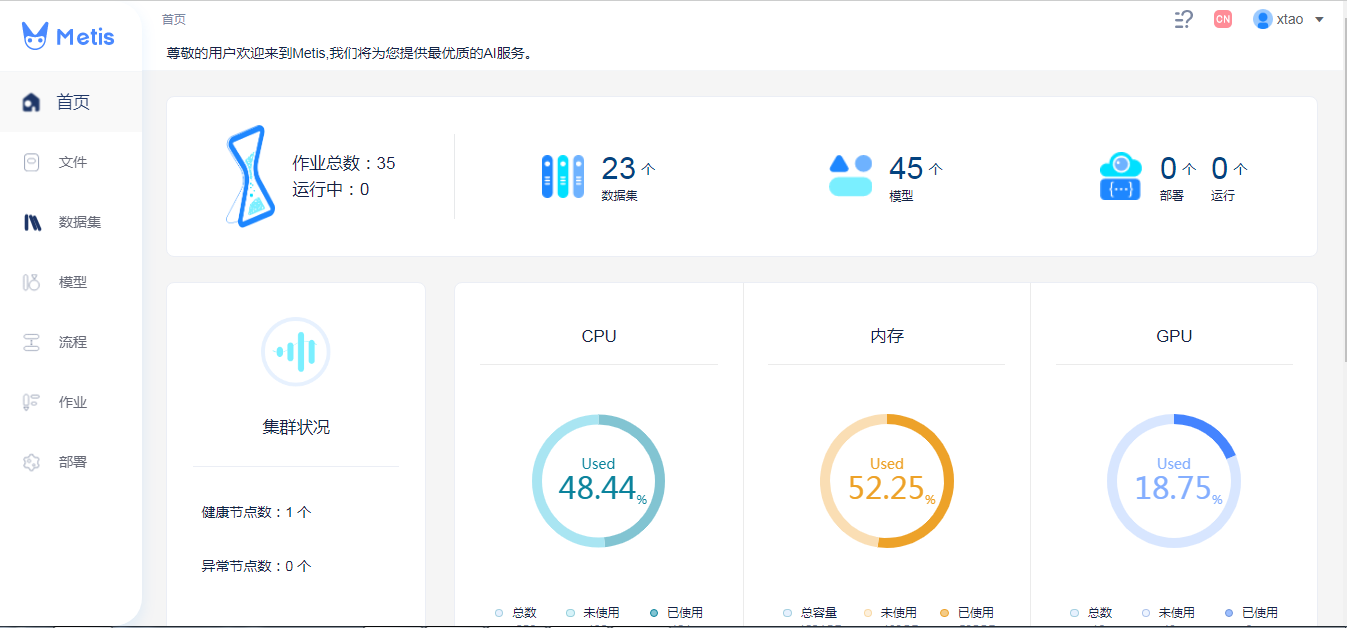
2. 数据集描述
本次分析选取TCGA数据集中乳腺癌的RNA表达量作为自变量以及样本是否为癌症组织样本作为响应变量。过滤掉存在缺失值的数据后,共保留样本XXX个——及行数,作为特征的基因表达量作XXX列。该数据集反应了高通量技术手段下,生物信息大规模数据挖掘的一个主要问题,即样本数量一般而言远远小于特征数量。而特征中有明确作用的其实只占很少的比例,绝大部分特征可以忽略。
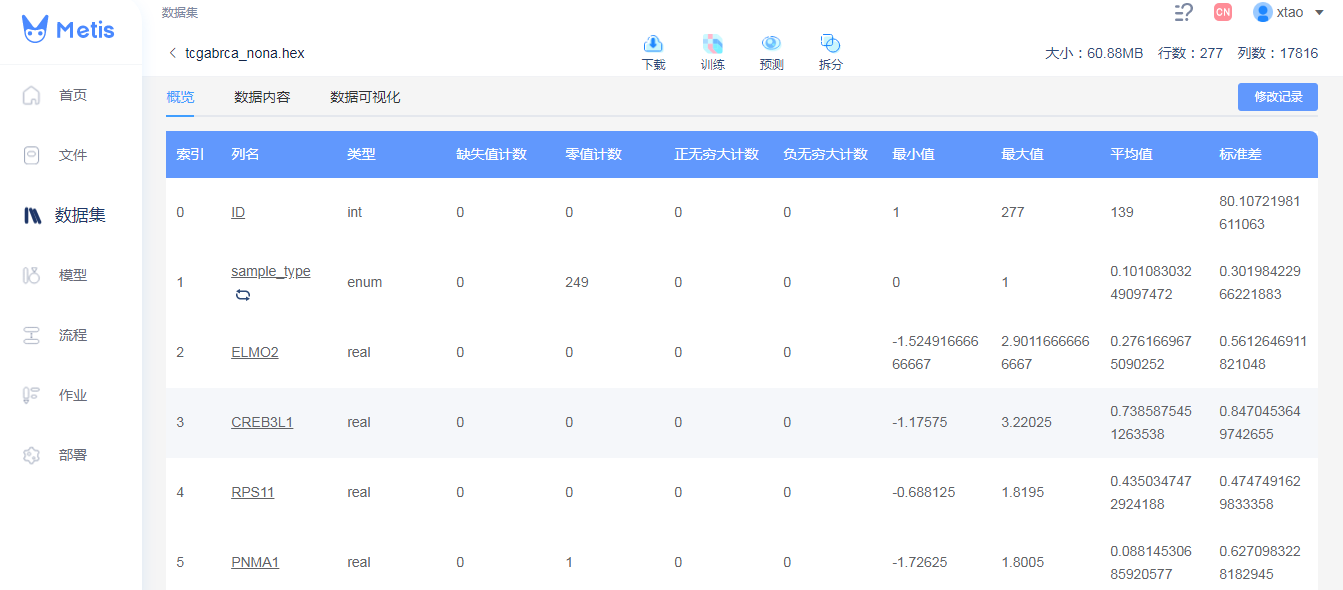
因此,在构建模型之前需要通过一定的手段对特征变量进行筛选。
3. 分析概述
3.1 特征选择
一般意义上的特征选择方法较多,对于特征数量相对较少的情况,通常可采用数据可视化的方式对特征情况进行直观地可视化展示,再进一步进行筛选。而对于生物信息数据而言,大规模的数据可视化展示反映的信息相对有限,而选择标准也难以确定。因此该方法并不是最主要的方式。
LASSO回归作为线性模型的一个实例,其约束条件决定了会排除无关变量。因此广泛应用于特征变量的选择上。
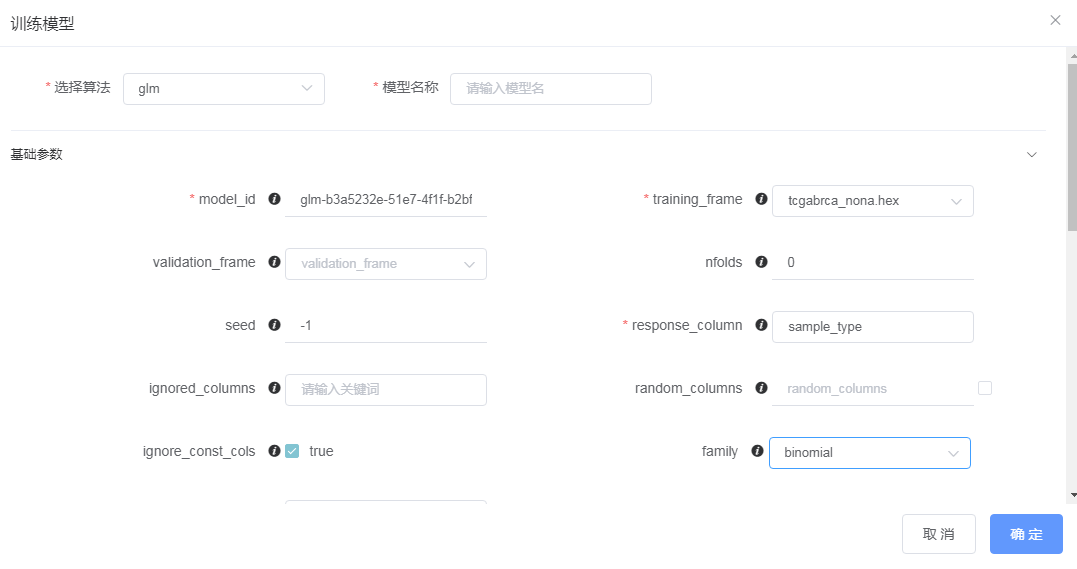
其中较为关键的参数包括
| 参数名称 | 对应值 | 含义 |
|---|---|---|
response_column |
sample_type | 响应变量 |
family |
binomial | 回归类型设定为二分类 |
alpha |
1 | 设定α为1,表示采用L1正则 |
nlambdas |
100 | 尝试的λ的个数 |
lambda_search |
true | 自动搜索最优λ值 |
除了LASSO回归之外,原则上也经常应用随机森林方式进行变量筛选,在此不再赘述,今后会陆续向广大读者进行介绍。
3.2 特征选择
上述操作完成后,得到了效应值不为0的特征即为备选特征。通过Metis中特征选择,可以直接对特征进行选择后,构建新数据集用于进一步模型构建。
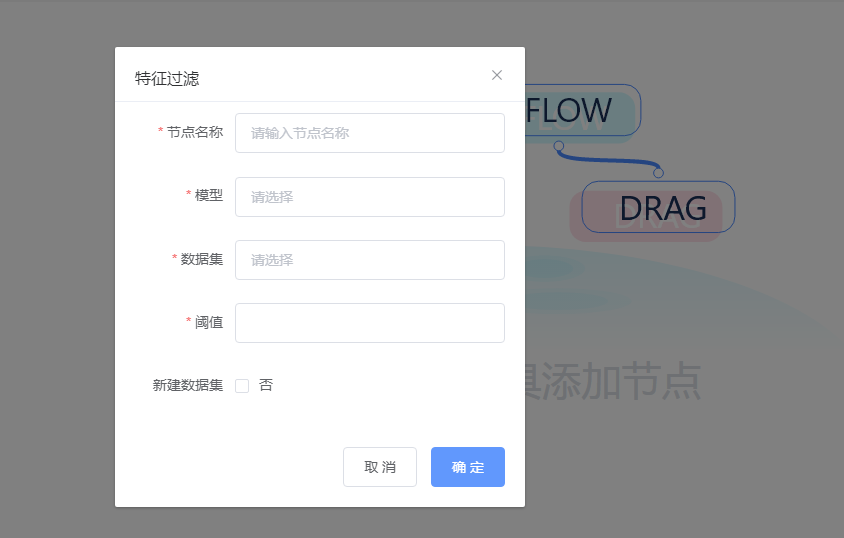
3.3 模型构建
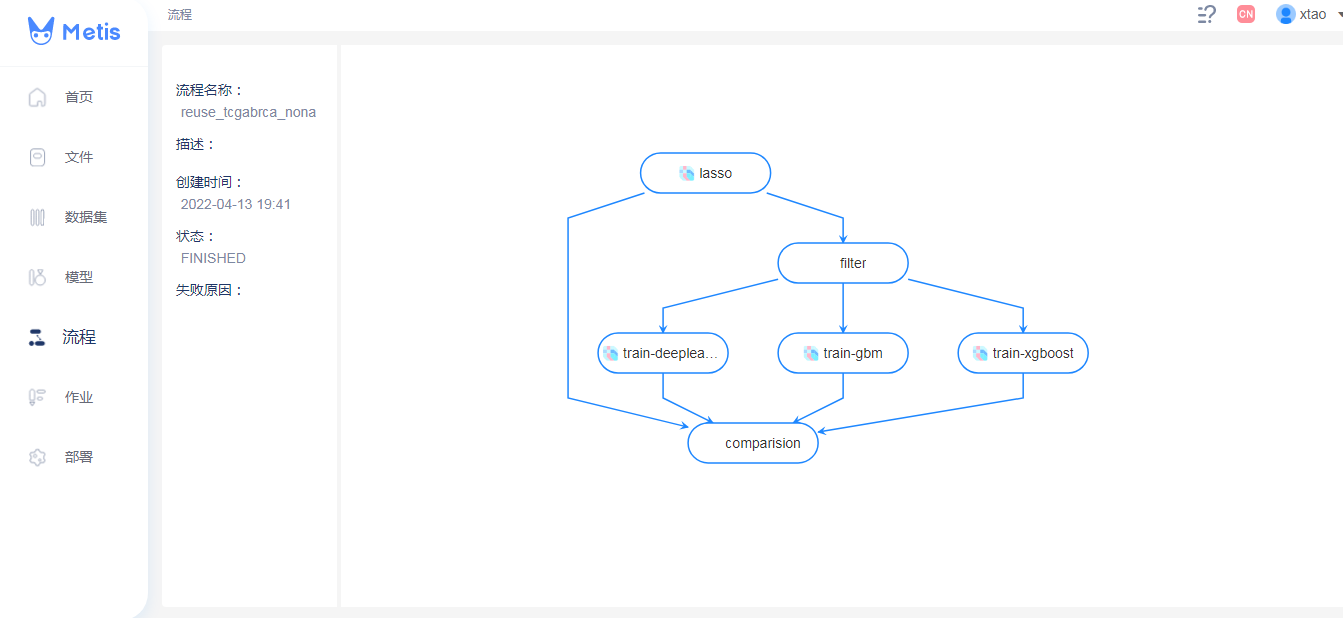
特征选择完成后,即可根据新数据集通过深度学习算法构建模型。在Metis平台上,用户可以实现目前绝大多数的机器学习算法,并且可以实现同一数据集,同时构建不同算法背景的模型。
例如对上面的数据集,可以采用三种不同的深度学习算法,进行模型构建,并实现模型之间比较。
4. 小结
通过上面的例子,初步展示了基于Metis 平台的生物信息数据机器学习模型构建过程。今后,我们会围绕着Metis平台的其他功能,进一步向各位读者介绍生物信息学数据机器学习相关案例。欢迎各位与我们进行交流讨论。