如何用好内存资源
相比CPU,内存(Memory)是更复杂的硬件资源,原因在于操作系统对两种资源的处理方式不一样。虽然CPU和Memory都可被多个进程分时共享,但共享的代价差别很大,这在很大程度上影响了用户对两种资源的使用。
操作系统的内存魔法
为了回答用户关于内存使用的问题,我们需要先了解操作系统的内存管理机制。
内存分层体系
冯诺依曼计算机体系结构的要点是存储程序计算,其中内存承载程序指令和数据,是关键的性能影响因素。现代操作系统采用内存分层体系,利用程序执行和内存访问的局部性原理最大化高速内存设备的利用率,优化系统整体性能。下图展示了内存分层体系结构:
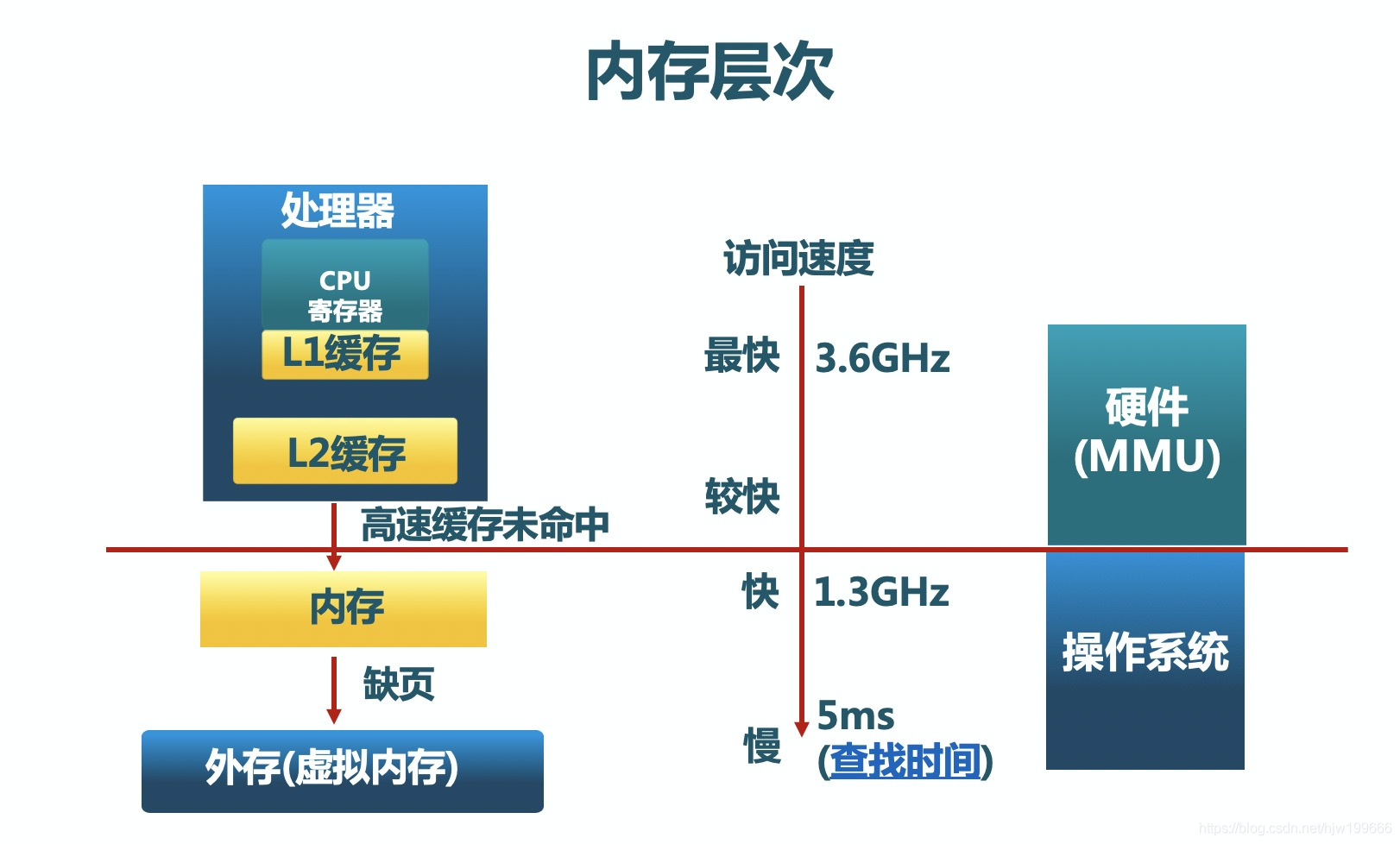
这个体系中各级存储设备的性能差别有多大呢?我们祭出一组Google大牛Jeff Dean在演讲中公布的性能数字:

从上面的性能数字不难推测,如果我们想办法将最有可能被马上访问的热数据加载到内存,将冷数据存储在相对低速设备中,可以在保持现有成本的前提下最大化用户的性能体验。这就是内存分层体系的指导思想。这个思想暗含的前提是计算机程序运行具有局部性特征。什么是局部性呢?通俗的说就是刚刚执行过的程序指令很大概率被再次运行,刚被访问过的内存地址很大概率又会被访问。在这个假定下,操作系统将很久没有被访问的数据从内存交换到硬盘上,释放出内存空间承载访问频率高的数据,实现了硬盘级别的成本和内存级别的性能。
为了实现这个策略,操作系统采用了虚实策略, 即将内存分为虚拟内存和物理内存。程序猿在C、C++、Java中malloc或者new分配的都是虚拟内存,是一个逻辑地址区域,并没有物理内存与之对应。这些区域只要不访问,就不会给它们映射物理内存。一旦程序访问未被映射的虚拟内存区域,就会触发硬件的缺页中断page fault,陷入到操作系统内核。操作系统分配需要的物理内存,和进程的虚拟地址对应起来。这样程序猿意义上的内存真正与机器物理内存对应上了。记录虚拟地址与物理地址映射的内存区域叫做页表(page table),它被CPU硬件的内存管理单元(MMU)引用。MMU决定着虚拟地址对应的物理地址是否存在或者有效,并触发缺页中断,让操作系统介入处理。
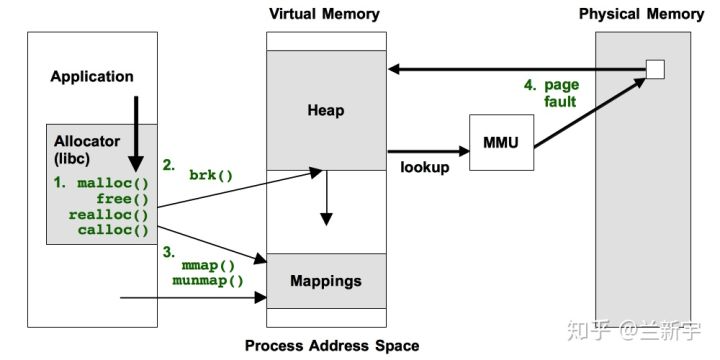
虚实内存映射是策略的第一个方面,解决动态分配问题。操作系统还需要解决内存的释放和回收问题。如果物理内存不够了,操作系统会通过策略或算法搜索不经常访问的物理页面,或者最近不会访问的物理页面,将该物理内存区域上的数据写到硬盘上的交换区域(swap)。然后操作系统修改页表映射记录,说明该虚拟地址区域对应的数据存在硬盘的具体位置。这样物理页面就回收给其它进程或者进程的其它虚拟地址区域使用。操作系统管理所有进程的虚拟地址空间、机器物理内存和交换区域,并记录哪些虚拟地址没有映射,哪些映射过但是被交换出去了。这样当虚拟地址再次被程序访问,触发缺页中断的时候,操作系统在缺页中断page fault的处理程序中,通过查看页表找到数据位置,重新映射物理内存,并将数据从交换区域恢复到物理内存。下图展示了这个过程:
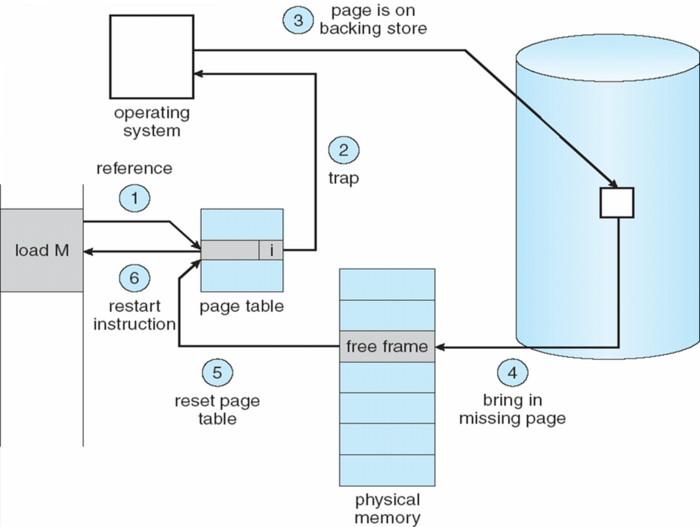
从应用程序的角度看,地址空间的内容从来没有发生变化,程序也按照既定的顺序执行。唯一的差别是程序计算的总时间变长了,变化程度取决于被缺页中断打断的次数。从操作系统的角度看,程序在缺页的时候被停顿了一下,缺页中断处理完后重新执行了被打断的程序指令。这是典型的以时间换空间。这样做的好处是程序猿可以使用比机器物理内存大的多的地址空间。机器物理内存只有128G,多个进程的虚拟地址空间加起来可以到PB级。
魔法为什么有效?
操作系统玩了一个复杂的魔法,目标是让尽可能多的数据在物理内存中,让用户程序可以使用比物理内存多的多的地址空间,获得高性价比。有一句俗话说,世界上没有免费的午餐。内存魔法不是没有代价。每一次缺页中断都会降低程序的性能,因为需要花费额外的时间分配内存。如果数据在交换区,还需要花费更长的时间从硬盘读数据。内存分层体系的实际效果,取决于两者综合后的结果。它的有效性依赖下面的假定:
- 程序局部性:程序的执行和内存访问在一定时间段倾向于访问一个局部区域,这意味着程序访问交换出去的地址空间的概率较低,缺页中断的总代价较低。
- 所有进程总工作集(
Working Set)不会超过物理内存大小太多:所谓进程的工作集,指的是在一个特定的时间段内一个进程所需要的物理内存数量。在这个假定下,只要操作系统足够聪明,就能保证用户程序的工作集(working set)尽可能在内存中,损失在缺页中断处理的代价将维持在可接受的程度。
魔法失效?
真实世界没有万能魔法。所有假定都可能被打破。我们实际中经常遇到内存引起的问题,原因在于假定失效造成了操作系统的内存共享经济破产。主要的原因有哪些呢?
局部性随规模增大降低
之前介绍过,程序局部性意味着刚加载到内存的数据足够用一段时间。与局部性对应的是随机性,即程序倾向于随机访问数据。随机性带来的结果是刚换出去的物理页马上会被访问,需要从硬盘上读回来,这样数据被反复交换和加载。
操作系统被多个用户程序共享,用户程序可能创建多个线程。对一个线程来说程序仍然有局部性,但是所有线程的聚合行为呈现出随机性。线程越多,随机性越明显。随着CPU性能增加,CPU的核心数越来越多,用户程序的线程越来越多,随机性持续增加,局部性持续降低。当局部性降低到一定程度,一旦工作集达到一定大小,内存问题就变得很严重。
数据规模变化造成工作集大小失控
现代计算的发展趋势是从科学计算向数据处理转换。很多程序为了编程简单,不考虑数据规模,一次性加载所有数据到内存计算。这样造成应用程序内存使用大小与处理的数据量成正比。当数据量增加,工作集远远超过内存大小。不幸的是数据规模随硬件增加的速度超过了开发者修改程序的速度。所以很多旧时代开发的程序处理新时代的大数据常常造成内存问题。
性能变化造成工作集大小失控
实际中常常有人会问:“我的程序处理的数据没有变化,为什么两次运行内存使用不一样?”。答案在于这两次运行不是完全相同的。一种典型的情况时你两次运行启动的线程不一样。5个线程并行处理的工作集和3个线程并行处理的工作集大小可能差别很大。另一种情况是加载数据的性能发生了变化,这样程序同一时刻处理的数据量变大了,造成工作集增大。
生产环境的内存魔咒
内存可能造成哪些问题?
因为前述的原因,在现代计算密集型或者数据密集型生产环境中,内存资源使用不善常常引发很多问题,笔者谓之内存魔咒。下面这些是很常见的现象:
- 程序性能降低:首先比较常见的是程序性能降低,运行时间远超过经验值和期望值。如果程序工作集过大,操作系统花大量的时间在程序的内存与硬盘交换区之间倒腾数据,做了大量的无用功。每一次交换意味着程序被调度进入等待,放弃
CPU,停止运行。这写问题可以通过各种工具来发现。如果程序的大多数时间花在等待数据页换入,性能就会严重降低。 - 系统运行缓慢:如果进程总工作集远超出物理内存总量,整个系统大量的时间花在数据交换。这个现象在操作系统理论上有个专门的名词颠簸(
thrashing)来描述。这种情况下整个系统运行卡顿,无论是程序计算还是用户响应都变慢。 - OOM和不确定错误:如果问题进一步严重,操作系统必须牺牲若干个内存占用量大的进程来避免继续颠簸。这种情况下会有进程被杀死。操作系统尽可能回收物理内存,恢复性能。
- 死锁或者死机:操作系统虽然控制着整个系统的运行,但并不能为所欲为。它的行为也受到规则约束。例如保证数据可靠性和一致性就是不能违背的规则。这个规则指的是操作系统的文件系统接收应用程序的
write操作,一旦确认操作成功返回给调用者,在数据写到设备之前不能丢弃数据。如果需要回收的物理页面被这些数据占用,系统必须通过文件系统的sync操作,确保数据落盘。但是文件系统的IO操作很复杂,例如有可能向一个分布式文件系统写数据,本身需要额外的内存分配。这个时候内存已经很紧张了,不能支持更多的内存分配。这就是所谓的死锁(有兴趣的同志请参考“系统架构面面观”)。我们常说的死机就是一种死锁。一旦操作系统死锁,系统再也无法恢复,除非重启机器。
为了解决上述内存滥用造成的系统问题,Linux操作系统引入了一种宏观调控机制cgroup,为内存分配的自由主义经济行为加入了宏观调控机制。
宏观调控手段cgroup和OOM
现代Linux操作系统内核提供了cgroup机制。每个程序从属于某个cgroup。每个cgroup可设置资源限制和配额,能够调控cpu、内存、io、网络和其它硬件设备的使用。操作系统运行期间,内核统计所有进程通过系统调用分配或释放的资源,记录在对应的cgroup中。如果资源使用超过限制,内核根据策略采取相应的行动限制进程使用,或者干脆杀掉进程保护其它进程的安全。
关于内存,cgroup支持:
- 软限制(
soft limit):如果cgroup的内存使用量超过该值,马上启动回收过程,避免内存使用超过硬限制。 - 硬限制(
hard limit):如果cgroup的内存使用量超过该值,则选择kill该cgroup中内存使用量较大的若干进程。这就是OOM(out of memory)机制。
这些限制和配额可以在内存、内核内存、内存加上交换区等多个粒度上进行配置。它帮助操作系统及早发现并处理内存使用失控的进程,确保整个系统的稳定性。
如何配置内存资源?
那么我们该如何给自己的应用程序申请内存资源呢?首先是弄清楚自己的程序内存使用状况,然后根据一些原则估算进程可能的内存使用量,作为资源申请的基础。
分析程序一次运行的内存占用
进程实时内存占用情况
运行top -p pid命令可以观察进程当前虚拟内存和常驻内存部分大小。典型的运行结果如下所示:
Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
%Cpu(s): 1.9 us, 0.4 sy, 0.0 ni, 97.6 id, 0.1 wa, 0.0 hi, 0.1 si, 0.0 st
KiB Mem : 19758057+total, 5153196 free, 14569828 used, 17785755+buff/cache
KiB Swap: 13421772+total, 13190467+free, 2313056 used. 17702057+avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2561630 root 20 0 49.453g 729272 7116 S 0.0 0.4 81:52.19 java
上图中的重要关注的指标包括:
- VIRT: 进程使用的虚拟内存总量(单位KB)。通常情况下,这一项远大于
RES项。 - RES: 进程正在使用的、未被换出的物理内存大小(单位KB),事实上就是进程当前的工作集。
- SHR: 共享内存大小(单位KB)
- %MEM: 进程使用的物理内存占系统总物理内存的百分比
原则上讲,用户申请的资源不应该低于RES值。
进程生命周期内存占用情况
运行cat /proc/pid/status命令可以输出进程到目前为止整个生命周期的情况。典型的运行结果如下所示:
[root@Cc2Apc ~]# cat /proc/2561630/status
Name: java
State: S (sleeping)
Tgid: 2561630
Ngid: 0
Pid: 2561630
PPid: 2561629
TracerPid: 0
Uid: 0 0 0 0
Gid: 0 0 0 0
FDSize: 256
Groups:
VmPeak: 51854904 kB
VmSize: 51854900 kB
VmLck: 0 kB
VmPin: 0 kB
VmHWM: 912652 kB
VmRSS: 729272 kB
RssAnon: 722156 kB
RssFile: 7116 kB
RssShmem: 0 kB
VmData: 51799384 kB
VmStk: 132 kB
VmExe: 4 kB
VmLib: 17064 kB
VmPTE: 3540 kB
VmSwap: 152344 kB
Threads: 265
SigQ: 2/771683
SigPnd: 0000000000000000
ShdPnd: 0000000000000000
SigBlk: 0000000000000000
SigIgn: 0000000000000000
SigCgt: 2000000181005ccf
CapInh: 00000000a80425fb
CapPrm: 00000000a80425fb
CapEff: 00000000a80425fb
CapBnd: 00000000a80425fb
CapAmb: 0000000000000000
Seccomp: 2
Cpus_allowed: ffffff,ffffffff
Cpus_allowed_list: 0-55
Mems_allowed: 00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000003
Mems_allowed_list: 0-1
voluntary_ctxt_switches: 13
nonvoluntary_ctxt_switches: 3
上图中与内存相关的重要指标包括:
- VmPeak: 代表当前进程运行过程中虚拟内存的峰值。
- VmSize: 代表进程现在正在占用的虚拟内存。
- VmLck: 代表进程已经锁住的物理内存的大小,锁住的物理内存不能交换到硬盘。
- VmPin: 进程中被
pin住的虚拟内存大小。 - VmHWM: 进程得到分配的物理内存的峰值,应该是到目前为止的
VmRSS的最大值。 - VmRSS: 进程现在使用的物理内存。
- RssAnon: 进程占用的物理内存中的匿名部分的大小,可以理解为
RSS中出去文件和共享内存占用的部分。 - RssFile: 进程占用的物理内存中用于文件映射的部分的大小。
- RssShmem: 进程占用的物理内存中共享内存的部分的大小。
- VmData: 表示进程虚拟内存中的数据段的大小。
- VmStk: 表示进程虚拟内存中的堆栈段的大小。
- VmExe: 表示进程虚拟内存中的代码段的大小
- VmSwap: 进程占用Swap的大小。
用户应该特别注意VmHWM,它是进程到目前为止的最大工作集,物理内存资源申请不应该小于这个值。另外VmPeak也应该注意,它表明了潜在的swap的大小。
如何估算程序下次运行的可能内存用量?
前面所述的进程的实际物理资源使用是特定一次运行的数据。实际中很多程序的内存使用量,可能和处理的数据、并行度或者其它参数有关。用户应该根据实际配置,动态估算内存使用量。典型的情况有下面几种:
- 数据加载处理型程序:应该根据输入数据的大小,按照比例估算物理内存用量。尤其是对那些会一次性将数据加载到内存中进行处理的程序,数据大小可能是决定性的因素。
- 多线程计算类程序:如果程序是多线程运行,占用的内存量可能和同时运行的线程数有关系。用户应该根据一次性运行的观察值,与线程数有关的参数结合,估算内存占用量。