一切靠自己的MPI框架
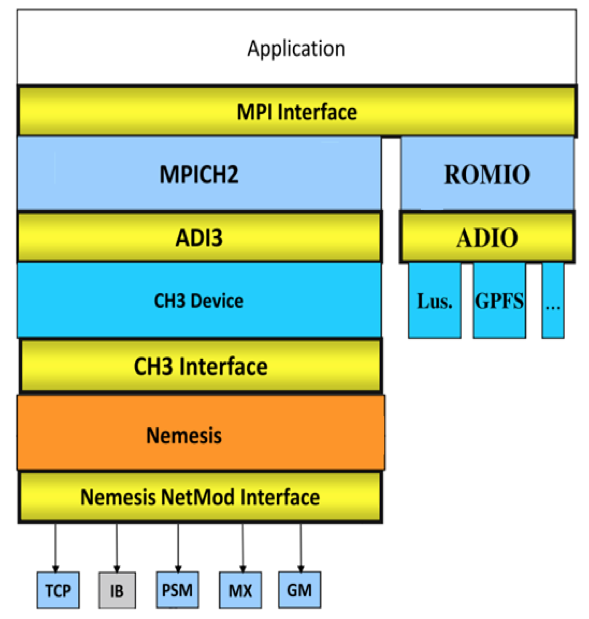
MPI是高性能计算常用的实现方式,它的全名叫做Message Passing Interface。顾名思义,它是一个实现了消息传递接口的库。MPI作为编程库很丰满,作为计算框架很骨感。它的好处在于一切自己动手,不利也在于一切全靠自己。
本文的目的不是探讨如何使用MPI,MPI标准是这方面最有参考价值的文档。本文笔者仅仅讨论它在并行编程上的特点,帮助用户决定何时或在何种场景下使用MPI。
什么是MPI?
MPI是一个跨语言的通讯协议,支持高效方便的点对点、广播和组播。它提供了应用程序接口,包括协议和和语义说明,他们指明其如何在各种实现中发挥其特性。从概念上讲,MPI应该属于OSI参考模型的第五层或者更高,他的实现可能通过传输层的sockets和Transmission Control Protocol (TCP)覆盖大部分的层。大部分的MPI实现由一些指定的编程接口(API)组成,可由C, C++,Fortran,或者有此类库的语言比如C#, Java或者Python直接调用。MPI优于老式信息传递库是因为他的可移植性和速度。
MPI标准也不断演化。主要的MPI-1模型不包括共享内存概念,MPI-2只有有限的分布共享内存概念。但是MPI程序经常在共享内存的机器上运行。MPI有很多参考实现,例如mpich或者openmpi。
同步是重点也是难点
顾名思义,MPI是基于消息传递的并行编程,它提供了语义丰富的消息通信机制,包括点对点、组播和多播模式。用户程序利用这些接口进行进程之间的数据移动、聚集、规约和同步。MPI标准规定了这些接口的调用规范和语义,不同的实现(例如mpich或者openmpi)可能采用不同的优化策略。
点对点通信
点对点通信指的是两个进程之间的通信,可用于控制同步或者数据传输,例如MPI_Send和MPI_Recv。
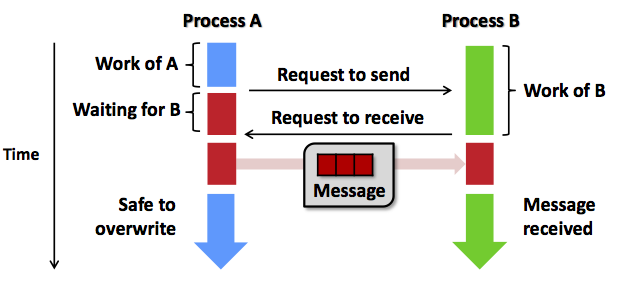
如上图所示,两个进程计算结束后,相互交换消息后,进行下一阶段的计算。这是MPI典型的工作模式。
点对点通信有同步(阻塞blocking)版本和异步(非阻塞non-blocking)版本。阻塞对发送端和接收端的意义不一样。MPI_Send返回意味着应用程序发送数据结束(至少数据已存储到系统缓冲区),应用程序缓冲可以重用或者覆盖,但不一定意味着接收者收到了数据。MPI_Recv返回则意味着数据已经接收到应用程序的缓冲区,可以使用了。非阻塞接口的意义在于操作马上返回,继续后续阶段的计算。当程序要求操作必须确认完成时,调用相应的测试接口(例如MPI_Wait)阻塞等待操作完成。异步编程相对麻烦,但是它使得计算和通信可以一定程度重叠,降低了数据同步带来的运行时间开销。
聚集通信(Collective Communication)
聚合通信包括了一对多、多对一和多对多的通信方式,常用于一组进程之间的数据交换。MPI提供了如下的聚合通信接口。
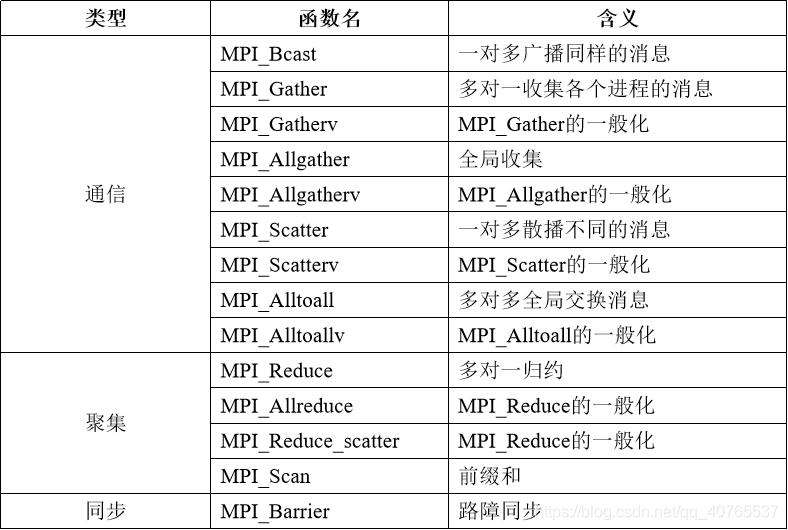
聚合通信接口的语义与进程的拓扑结构有关系。参见后续章节,当MPI程序启动后,每个进程会分配一个唯一的序号(rank)。聚合通信常常需要指定一个协调者(例如rank 0进程),由它负责将数据发送给所有进程(包括它自己)。我们以接口MPI_BCAST为例,它将数据从根进程发送到所有其它进程(包括根进程自己)。所有的进程都调用MPI_BCAST,如下例子所示:
## Broadcast 100 ints from process 0 to every process in the group.
MPI_Comm comm;
int array[100];
int root=0;
...
MPI_Bcast(array, 100, MPI_INT, root, comm);
...
它的一个典型实现如下图所示:
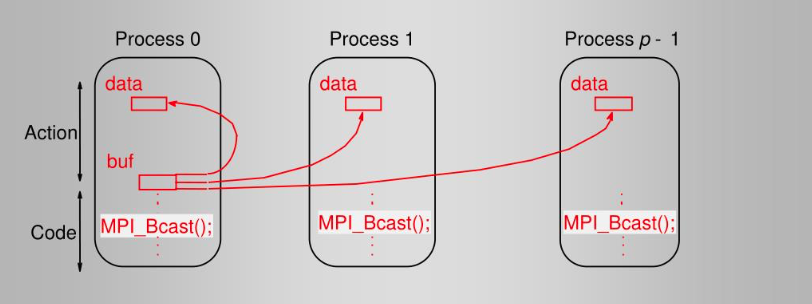
虽然每个进程都调用了MPI_Bcast,但是根进程负责广播数据,其它进程接收数据。接口MPI_Gather行为恰好相反,每个进程将数据发送给根进程。例如如下的代码实现了一个典型的聚合数据的过程:
MPI_Comm comm;
int gsize,sendarray[100];
int root, myrank, *rbuf;
...
MPI_Comm_rank(comm, &myrank);
if (myrank == root) {
MPI_Comm_size(comm, &gsize);
rbuf = (int *)malloc(gsize*100*sizeof(int));
}
MPI_Gather(sendarray, 100, MPI_INT, rbuf, 100, MPI_INT, root, comm);
...
对应的典型实现是:
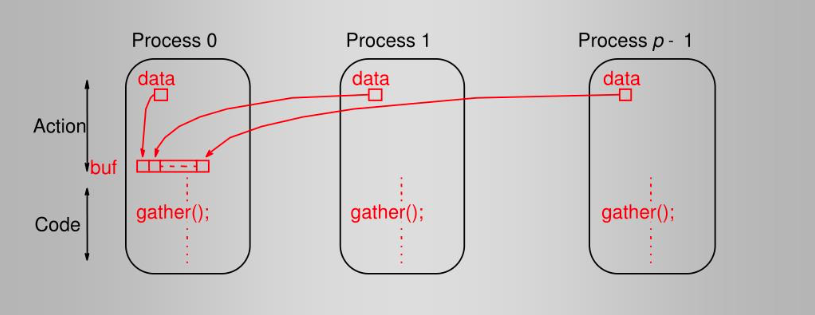
从中可以看到MPI聚合通信的编程模式:每个程序独立完成一定的计算工作,到达交汇点,同时调用聚合通信原语(primitive)完成数据交换,然后根据结果进行后续计算。当计算规模较大,聚合通信的性能非常关键,不同的MPI实现框架实现了不同的优化方案。上图描述的只是最直接和简单的实现方式,实际中往往采用更复杂的拓扑结构例如树形结构、环形结构来达到更好的性能。
同步
某些场景下,多个进程需要协调同步进入某个过程。MPI提供了同步原语例如MPI_Barrier。所有进程调用MPI_Barrier,阻塞程序直到所有进程都开始执行这个接口,然后返回。由此可见它的作用就是让所有进程确保MPI_Barrier之前的工作都已完成,同步进入下一个阶段。
MPI程序如何运行?
编程模型(Programming Model)
从前面的例子,大家可能发现MPI程序的编程模式,那就是迭代式的“计算 + 通信”。如下图所示,程序可以分为计算块和通信块。每个程序可以独立完成计算块,计算完成后进行交互,即通信或者同步。交互完成后进入下一个阶段的计算。直到所有任务完成,程序退出。
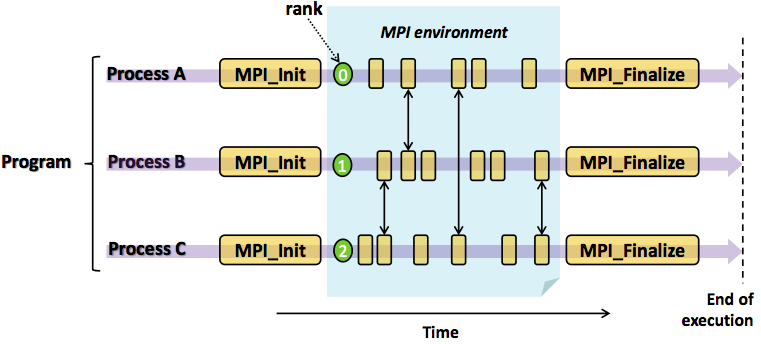
上篇我们讨论了分治法,即并行程序的任务分解和结果合并。MPI程序怎么实现任务分解呢?事实上,MPI框架只是提供了通信机制,即任务之间同步和通信的手段。计算任务怎么分解,数据怎么划分,计算怎么实现,任务怎么合并等等问题都由程序开发者自己决定。MPI框架在程序启动的时候,为每个程序副本分配了唯一的序号(rank)。通常程序可以通过获取rank确定自己是谁,根据rank决定谁该做什么工作。
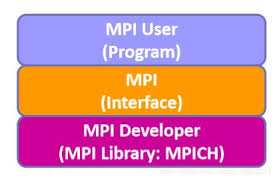
由上图可以看出,一个典型的MPI程序由用户程序部分链接MPI库构成,计算任务本身的算法实现、任务分解和合并实现在用户程序部分,与MPI无关,也不受MPI限制。所以说,MPI框架提供给编程者最大的灵活性,实现了最小的封装。
调度和PMI
虽然MPI标准主要关注通信和进程间交互,但是资源管理和进程调度问题是任何一个分布式计算的框架必须解决的问题。进程管理接口PMI (Process Management Interface)定义了MPI程序与运行时环境的交互接口,尝试解决资源管理问题。PMI有很多具体实现,典型的例子是Hydra进程管理器,它是PMI-1标准的具体实现。任何一个实现了PMI标准的进程管理器负责的功能包括资源管理、启动和清除MPI用户进程、运行环境初始化等等。
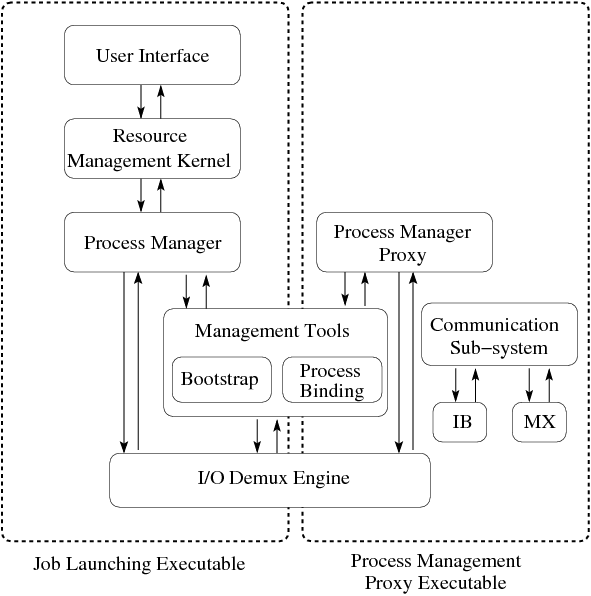
如上图所示,Hydra框架提供进程启动工具和PMI代理程序。当用户运行mpiexec命令启动MPI程序,同时指定一个主机列表。Hydra框架通过资源管理器(例如PBS等)分配或者验证节点资源,在每个节点上启动代理(hydra proxy)进程。代理进程互相连接,形成集群,设置执行环境,启动用户的MPI程序。用户MPI程序启动后,通过内置的PMI客户端与启动它的Hydra代理建立反向连接。在这个过程中,MPI进程的拓扑结构建立起来,每个进程拥有独立的rank,开始后续的并行执行。下图展示了Hydra进程管理器的启动过程,其中Hydra代理进程建立了一个树形拓扑。
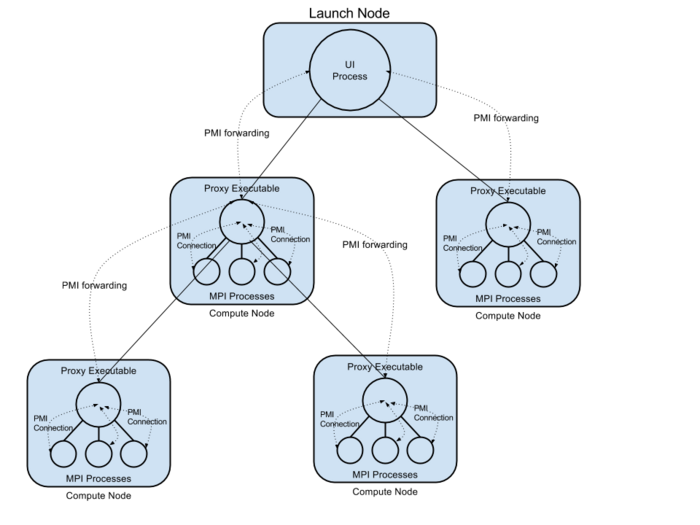
一旦上述拓扑建立,完成了用户进程的启动,框架的工作完成,用户程序的计算开始。直到某个用户进程故障退出,或者用户主动停止程序,进程管理器再度介入,完成错误处理和清理工作。
容错
所有的分布式系统都需要容错。那么MPI程序如何容错呢?不同的框架实现提供了不同程度的容错支持。主要的方式是快照(checkpoint)和程序重启机制。例如Hydra框架基于Berkerly的BLCR快照和重启库(checkpoing and restart)实现MPI程序的快照功能。例如用户通过下述方式启动程序,指定快照机制和快照数据目录:
mpiexec -ckpointlib blcr -ckpoint-prefix /home/buntinas/ckpts/app.ckpoint -f hosts -n 4 ./app
当程序启动后,用户可以通过给mpiexec程序发送信号sigUSR1启动快照,Hydra也可以周期性的执行快照操作。Hydra框架根据启动时建立的PMI代理进程集群,为每个节点上的MPI用户进程生成快照,保存程序运行状态、文件IO状态或者网络状态,保存在指定的目录下。当程序出错退出,用户可通过执行下述命令从上一个快照重启程序,继续执行:
mpiexec -ckpointlib blcr -ckpoint-prefix /home/buntinas/ckpts/app.ckpoint -ckpoint-num 5 -f hosts -n 4
存储的一致性要求
某些场景下, MPI程序需要访问和共享分布式文件系统完成计算。MPI标准的MPI-IO部分定义了文件共享和访问接口,实现聚集IO(Collective IO),某些应用模式中提供了相比POSIX接口更好的性能。MPI-IO标准中的某些接口可能造成不同进程对同一个文件的不同部分并发访问。为了确保并发读写的一致性,MPI-IO标准的原子性模式(Atomic Mode)定义了较严格的一致性。某些MPI实现框架要求底层文件系统具备较强的一致性或者锁机制,以确保正确的原子性模式的实现。因此使用MPI-IO且有严格一致性要求的计算应用对共享的文件存储施加了较为严格的一致性要求,用户必须谨慎选择文件系统类型。
容器时代的MPI
传统的高性能计算大多采用MPI模型编程,通过传统调度器如SGE、SLURM、PBS投递计算任务。随着容器技术的应用和云原生概念的兴起,容器化不但政治正确,确实简化运维和部署。那么怎么容器化MPI应用?通常有两种选择:
- 依赖调度器的云原生支持。这种方案依赖调度器自己的演进,且对用户选型增加了限制。
- 将传统的调度器部署在容器中,运行在类似
k8s的容器云中。这种方案的实质是调度器的容器化,无论是用户体验还是资源利用率都不是最优的。
极道Achelous的平台独辟蹊径,研发的Partisaner调度器与PMI框架(例如Hydra)深度整合,无缝支持MPI的容器化,且兼容mpich和openmpi。Achelous平台支持用户通过领域编程语言(WDL和BSL)将MPI程序嵌入到数据流中,成为数据处理的超级工具。在极道领域专用语言编写的程序中,MPI程序像汇编语言中的处理器基本指令一样即时动态运行,最大程度降低了它的使用门槛。