玩转系统的十八般兵器
有句成语说“工欲善其事必先利其器”,系统问题纷繁复杂,需要完善的工具、方法和系统来帮助定位和解决。操作系统级别的机制和工具是首要条件,是后续分析和自动化的基础。打铁先得锤子硬。本篇笔者结合自己的经验,和大家聊聊分析系统问题的工具和方法。
工具只提供数据不提供答案
无论是通过命令行手动分析,还是运维系统自动分析,包括玄之又玄的智能运维(AIPOS),基础都是数据。差别只是做分析和决策的是人还是程序。在真实的数据密集型和计算密集型的生产环境中,任何机制或者工具都不可能采集系统所有的事件,所以数据不是日志,它在本质上是系统行为和状态在某个层次的粗粒化。例如iostat看硬盘设备的读写带宽和占用率,返回的是一个时间段的宏观统计值,使用者需要根据经验或者系统的实现机制去分析潜在的原因。
事件、状态或性能?
分析目的不一样,采用的工具、方法和代价各不相同:
- 分析事件:确认某个事件是否发生,或者发生前后的状态是什么。通常我们使用
Trace类工具去解决这种问题。这类分析需要等待特定事件发生,时间不确定,对系统运行性能可能有较大影响,需要根据具体情况选择工具的参数。 - 分析状态:确认系统或者程序是否处于某个特定状态,例如故障、Hang或者死锁。通常需要结合工具与源代码才能精确确定问题。
- 分析性能:确认性能瓶颈或者热点,
perf或者Trace类工具都可以用来帮助寻找线索,使用者需要结合代码,修改代码再测试,不断迭代才有可能解决问题。
数据采集对系统的影响
数据收集的首要问题是数据收集的代价,即数据收集对生产系统的影响程度如何。不同工具因为其实现方式不一样,对系统造成的影响各不相同。iotop或者iostat等工具的数据收集在目标代码段执行过程中,或者状态切换的时候进行,代价较小,但是提供的信息粒度相对固定。dtrace或者systemtap 等工具支持用户插入自己的分析代码,会给系统造成一定程度的性能影响。这些工具通常提供选项控制采样频率或者尺度,使用者需要根据具体情况选择。
Linux提供了哪些工具?
Linux系统集成了大量的监控和分析工具帮助用户解决问题,大家根据需要自行选择服用。这些都是开发、调试、运维、杀人、放火必备技术。
- 性能调试工具如下图所示:
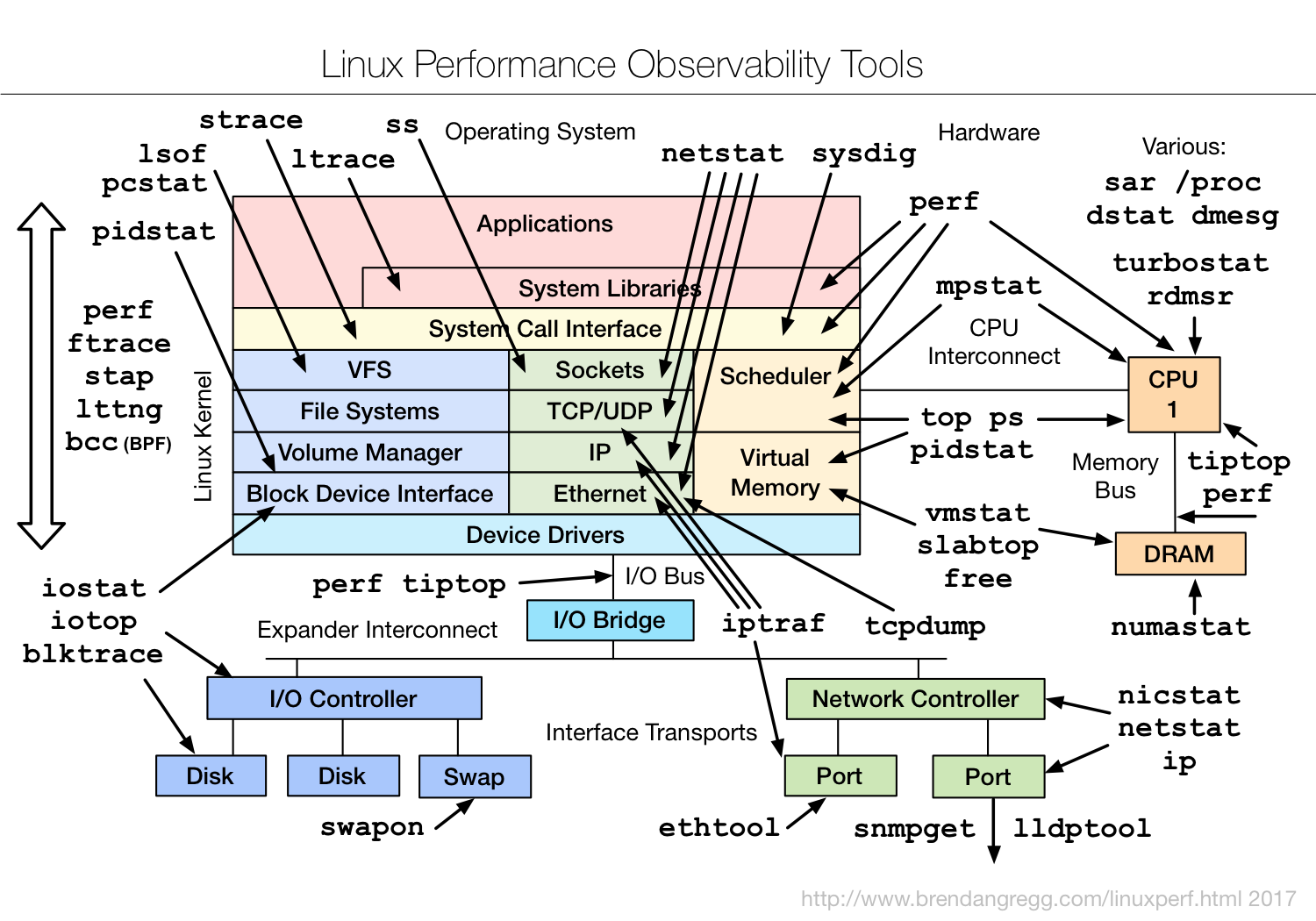
- Trace工具如下图所示:
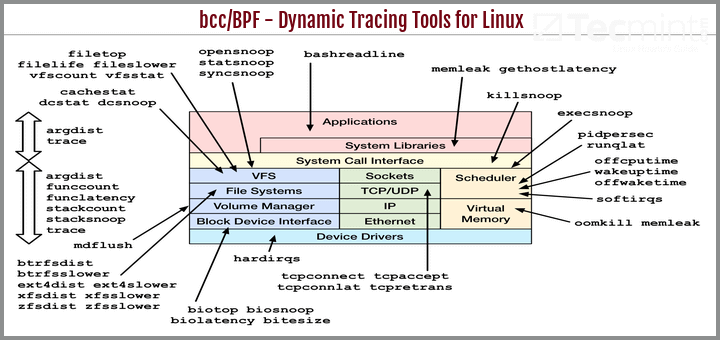
分析进程(process)问题
top
大家都比较熟悉top工具,它可以直接显示出当前系统的负荷和热点进程。典型的输出如下所示。
Tasks: 933 total, 1 running, 863 sleeping, 0 stopped, 69 zombie
%Cpu(s): 0.1 us, 0.1 sy, 0.0 ni, 99.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 19758057+total, 13079468 free, 25421992 used, 15907912+buff/cache
KiB Swap: 13421772+total, 13305742+free, 1160304 used. 16616251+avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2173545 marathon 20 0 61.767g 2.323g 63176 S 1.7 1.2 217:16.67 java
1659411 root 20 0 71876 37796 6756 S 1.0 0.0 203:54.46 etcd
2326128 root 20 0 2378924 55612 8984 S 1.0 0.0 2:28.02 resmon
845 root 20 0 122148 55752 49316 S 0.7 0.0 1601:35 systemd-journal
6571 root 20 0 4113028 182464 2648 S 0.7 0.1 1220:36 xtagent
1555697 root 20 0 4395944 50892 45504 S 0.7 0.0 48:13.91 srm-docker-exec
1569361 root 20 0 68704 35884 6796 S 0.7 0.0 194:34.26 etcd
2703451 root 20 0 147096 2872 1408 R 0.7 0.0 0:00.05 top
24168 root 20 0 113372 6960 4204 S 0.3 0.0 7:02.71 containerd-shim
440312 root 20 0 33.751g 8.570g 16552 S 0.3 4.5 7996:04 java
基于top的输出,大家应该关注一些重要的指标:
- 异常CPU利用率:除非纯计算类或者大量内存拷贝类任务,过高的CPU利用率都是不太正常的。尤其是某些系统服务、内核工作线程、中断类代码等等显示过高的CPU利用率意味着内核异常或者负荷过重,需要引起注意。
- 长时间维持低可用内存
free或者高Swap利用率:意味着内存相对不足,系统负荷过高,通常是系统卡顿、服务不能响应、网络心跳超时等的原因,可以进行更深入的Hang或者死锁分析。
proc文件系统
所有新的Linux系统上的/proc目录是一种文件系统,即proc文件系统。与其它常见的文件系统不同的是,/proc是一种伪文件系统(也即虚拟文件系统),存储的是当前内核运行状态的一系列特殊文件,用户可以通过这些文件查看有关系统硬件及当前正在运行进程的信息,甚至可以通过更改其中某些文件来改变内核的运行状态。 proc文件系统内容非常丰富,笔者建议用户重点关注下述信息。
进程信息
在/proc/pid下存储着特定进程的信息。每个进程占用一个目录,以其pid为子目录名。内容如下所示:
[root@Cc1Apc ~]# cd /proc/2173545
[root@Cc1Apc 2173545]# ls
attr clear_refs cpuset fd limits mem net oom_score projid_map sessionid stat task
autogroup cmdline cwd fdinfo loginuid mountinfo ns oom_score_adj root setgroups statm timers
auxv comm environ gid_map map_files mounts numa_maps pagemap sched smaps status uid_map
cgroup coredump_filter exe io maps mountstats oom_adj personality schedstat stack syscall wchan
其中目录fd包括进程打开的文件,environ包含进程的环境变量,task下面的子目录是进程的所有线程。status文件非常重要,其中包含有进程运行过程中的内存使用情况统计、context切换统计,信号处理配置等等。
负载信息
目录/proc/loadavg 含有关于CPU和磁盘IO的负载平均值,典型输出如下:
[root@Cc1Apc /]# cat /proc/loadavg
0.64 0.94 0.85 1/6730 2719127
其中前三列分别表示每1秒钟、每5秒钟及每15秒的负载平均值,类似于uptime命令输出的相关信息;第四列是由斜线隔开的两个数值,前者表示当前正由内核调度的实体(进程和线程)的数目,后者表示系统当前存活的内核调度实体的数目;第五列表示此文件被查看前最近一个由内核创建的进程的PID。
很多传统的调度软件(例如SGE/OGE)显示的负载,实际上是通过读取/proc/loadavg获取的数据。这个数据在一定程度上反映了系统负荷的真实状态,但是并不完整。例如它不能反映系统内存的负荷情况,而内存是影响系统稳定性和性能的最重要因素。这恐怕也是SGE类的传统调度软件往往将系统跑死的一大原因。
分析IO问题
iostat
很多时候,用户反映系统或者数据IO服务存在性能问题,工程师需要使用对应工具分析和定位问题。熟悉可以分析系统中硬盘的使用情况,判断是否硬件达到瓶颈。iostat是一个非常基本的工具。iostat是I/O statistics(输入/输出统计)的缩写,用来动态监视系统的磁盘操作活动。iostat的输出如下所示:
[root@Cc1Apc ~]# iostat -xd sda sdc
Linux 3.10.0-514.26.2.el7.x86_64 (Cc1Apc) 2021年07月15日 _x86_64_ (56 CPU)
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 147.42 224.38 25.11 39.63 751.59 3910.74 144.03 0.42 6.48 12.98 2.36 2.89 18.73
sdc 0.00 0.03 0.66 6.80 85.54 366.39 121.14 0.00 0.29 0.42 0.28 0.09 0.07
输出中有一些需要重点关注的项如下: • rrqm/s: 每秒进行 merge 的读操作数目。即 rmerge/s • wrqm/s: 每秒进行 merge 的写操作数目。即 wmerge/s • r/s: 每秒完成的读 I/O 设备次数。即 rio/s • w/s: 每秒完成的写 I/O 设备次数。即 wio/s • rsec/s: 每秒读扇区数。即 rsect/s • wsec/s: 每秒写扇区数。即 wsect/s • rkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。 • wkB/s: 每秒写K字节数。是 wsect/s 的一半。 • avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)。 • avgqu-sz: 平均I/O队列长度。 • await: 平均每次设备I/O操作的等待时间 (毫秒)。 • svctm: 平均每次设备I/O操作的服务时间 (毫秒)。 • %util: 一秒中有百分之多少的时间用于 I/O 操作,即被io消耗的cpu百分比
为了得到有意义分析结果,用户需要了解和积累基本的IO原理和性能数据。一般来说,首先是关注占用率%util,它表示采样过程中硬盘设备有IO没有返回的时间比率。如果比率高,说明硬盘上总是存在未完成的IO,也即设备忙。进一步分析设备忙,大致会有三种典型情况:
- 第一种典型情况是顺序大IO,这个可以反映在
rkB或者wkB比较高,svctm比较小。 - 第二种典型情况是随机IO,它的读写带宽
rkB/wkB都不会太高,但是svctm会比较高,相当于每次IO的平均延迟比较长。 - 第三种典型情况是观察到同样
%util的情况下,带宽和延迟同步变差了。这可能意味着硬件层面平均的变慢了,需要关注HBA卡、JBOD硬盘柜、SAS连接线等存储的硬件设施。
iotop
iostat分析的是硬盘设备的整体使用情况,很多时候需要回答的是某个程序为什么慢的问题。iotop 监控Linux内核输出的IO使用信息,并且显示一个系统中进程或线程的当前IO使用情况。它显示每个线程读写IO带宽,等待换入和等待IO的线程花费的时间的百分比。
iotop命令典型的输出如下(为了脱敏,命令行经过编辑省略了参数):
Total DISK READ : 0.00 B/s | Total DISK WRITE : 250.74 K/s
Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 2.33 M/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
34555 be/4 root 0.00 B/s 62.69 K/s 0.00 % 0.54 % ceph-mon …
1157824 be/4 root 0.00 B/s 5.97 K/s 0.00 % 0.14 % etcd …
468904 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.13 % [kworker/2:0]
1157857 be/4 root 0.00 B/s 8.96 K/s 0.00 % 0.11 % etcd …
1042681 be/4 root 0.00 B/s 2.99 K/s 0.00 % 0.02 % etcd …
34573 be/4 997 0.00 B/s 32.84 K/s 0.00 % 0.00 % python …
5177 be/4 nscd 0.00 B/s 2.99 K/s 0.00 % 0.00 % nscd
366061 be/4 wd 0.00 B/s 98.51 K/s 0.00 % 0.00 % java …
1026041 be/4 26 0.00 B/s 0.00 B/s 0.00 % 0.00 % postgres …
1093589 be/4 root 0.00 B/s 2.99 K/s 0.00 % 0.00 % docker -H …
382986 be/4 root 0.00 B/s 2.99 K/s 0.00 % 0.00 % docker -H …
iotop输出的是线程的IO等待情况。在Linux内核中,每当线程读写数据被阻塞将要进行“context”切换的时候,会在内核线程数据结构中记录开始时间,等待IO返回的时候计算花在该IO上的时间,并累加统计该线程花在IO等待上的总时间。因此iotop的数据总是和线程关联,且统计的是线程同步等待IO的数据,不能统计操作系统内核执行的由该线程发起的异步IO情况。所幸的是程序通过VFS访问本地文件系统、NFS或者硬盘设备的情况都可以统计到,能够解决实际中相当数量的问题。显示的总体数据中,Total DISK READ 和Total DISK WRITE的值一方面表示了进程和内核线程之间的总的读写带宽,另一方面也表示内核块设备子系统的带宽。Actual DISK READ和Actual DISK WRITE的值表示在内核块设备子系统和下面硬件(HDD、SSD等等)对应的实际磁盘IO带宽。
尤其值得注意的是可以显示出程序花在SWAPIN的时间比率。如果这个值过高说明系统总体物理内存不够,程序花了过多时间交换数据。在程序以容器方式运行的情况下,说明程序的物理内存限制相对于其虚拟内存来说太小了。这个项比较高的程序运行效率都不会太高。
如果有些程序显示比较高的IO等待率,本身没有文件读写调用,可能是mmap系统调用读写数据引起的。很多程序使用mmap映射文件到内存区域,在进程之间实现高速的数据传输。表面上看进程向mmap映射的内存区域写入数据,不会阻塞在IO上。实质上读写该虚拟内存区域,会触发操作系统的缺页异常(page fault),缺页异常的处理流程会分配和映射物理内存,当物理内存紧张需要引发内存回收的情况下,也可能阻塞在IO上,结果会限制进程的写操作,实现了限流(throate)。这也是动态平衡的一个例子。当然这也说明,基于mmap的进程之间通信在大量数据传输的情况下并不是内存拷贝级别的性能,操作系统当内存不够的时候必然sync数据到硬盘,然后性能降低到硬盘级别。
死锁分析
死锁分析的方法可以概括成看栈找环,即通过分析程序目前的调用栈,结合源代码看是否在资源上形成了依赖环(请参考系统工程之原理篇)。这是一种高级分析方法,面向的主要是掌握源代码的开发人员。不能掌握源代码的运维人员,可以从中得到线索帮助分析问题,但不能确定系统是否发生了死锁。
死锁分析没有太好的办法,唯手熟耳。
什么样的栈是可疑的?
一个程序无论是在用户态还是内核态执行,如果被卡住不能继续运行,通常是下面三种原因:
- 程序等待某个事件被切换出CPU,进入睡眠:例如用户态程序调用
pthread_cond_wait,进入睡眠,最后都会在内核栈上等待futex调用的返回。 - 程序等待某个IO操作返回,进入睡眠:例如程序调用
write或者read系统调用被阻塞住,内核栈上会体现为vfs_*类的操作不能返回。 - 程序等待某把锁,进入睡眠:如果是用户态程序,例如使用
pthread库的程序,内核栈上会出现futex相关的函数序列。如果是内核程序,则会出现lock相关的函数栈。
有一点需要注意的是,资源的依赖环并不一定会出现在栈上。因为栈上看到的是没有返回的函数调用序列。假设某程序进入函数func1,调用lock拿到锁A,执行func2,获取锁B,执行func3获取锁C的时候被阻塞,栈上会出现func1->func2->func3->lock wait C的类似序列,关于锁A和B的操作不会出现在栈上。发现可以栈后,必须通过梳理源代码才能找到精确的环。
查看特定程序内核栈
线上环境会经常性遭遇命令无法返回,程序卡住,或者程序杀(kill)不掉,背后的原因大概率是程序在内核态阻塞在某个事件、锁或者IO上。每个线程都有用户态栈和内核栈。当线程通过系统调用,或者因为调度陷入(Trap)到内核态的时候,就会使用内核栈。因此查看进程的proc文件系统的线程的stack可以确认这一点。你先找到进程的pid,然后运行命令cat /proc/pid/task/*/stack,可得到类似下面的输出:
[root@Cc2Apc ~]# cat /proc/1157833/task/*/stack
[<ffffffff810f5464>] futex_wait_queue_me+0xc4/0x120
[<ffffffff810f5fd9>] futex_wait+0x179/0x280
[<ffffffff810f80de>] do_futex+0xfe/0x5b0
[<ffffffff810f8610>] SyS_futex+0x80/0x180
[<ffffffff81697809>] system_call_fastpath+0x16/0x1b
[<ffffffffffffffff>] 0xffffffffffffffff
[<ffffffff810f5464>] futex_wait_queue_me+0xc4/0x120
[<ffffffff810f5fd9>] futex_wait+0x179/0x280
[<ffffffff810f80de>] do_futex+0xfe/0x5b0
[<ffffffff810f8610>] SyS_futex+0x80/0x180
[<ffffffff81697809>] system_call_fastpath+0x16/0x1b
[<ffffffffffffffff>] 0xffffffffffffffff
...
上图展示的栈没有显示出问题(即没有卡在内核栈上),大多数正常的进程都是这个状态。大家有兴趣可以去了解下futex这个系统调用。大多数用户态的事件或者同步操作(例如pthread中的锁和条件变量)都要基于它来实现,因此这个栈什么也说明不了。
需要注意的是你看到的是程序这一刻的栈,并不能确定程序卡住不动了。你需要多运行几次比较结果,或者结合其它信息判断是否线程栈始终处于这个状态。
分析所有程序内核栈
如果你要分析系统或者内核死锁的原因,看一个线程的栈是不够的。你需要打出当前系统中的所有线程的栈,找出异常的线程栈,然后通过结合内核源代码找到资源依赖或者锁的环。
echo t > /proc/sysrq-trigger
上述命令会将系统中所有的线程栈输出到内核的消息缓冲区,你可以通过dmesg查看。
分析用户态线程栈
例如Golang这样的编程语言通过自己的运行时(runtime)实现了用户态线程。Golang语言编写的服务可能卡在用户态线程上,即用户态线程之间死锁了,查看进程的内核栈不一定能发现问题。这种情况下需要通过工具dump程序所有用户态线程的栈,查找死锁环。幸运的是类似Golang这样的语言提供了非常丰富的库和机制,支持通过响应用户的信号量,将用户态线程栈输出到日志文件中。例如向Docker Daemon进程发送信号kill -sigUSR1 pid就可以将所有栈打印到日志中。
分析程序热点或者瓶颈
分析程序热点是性能分析和优化的必要工作。很多热点问题不可能仅仅依靠分析源代码解决。Linux系统提供了很多工具帮助用户收集运行时数据,分析性能瓶颈。
perf
Linux平台上的perf工具是常用的性能分析工具。大家可以访问 链接了解详细的使用方法。在环境中安装必要的调试符号信息(例如各种debug info包)就可以直接运行perf工具收集到目标程序的CPU占用数据。它的主要原理是周期性的采样线程栈,统计栈上的函数调用序列,得到CPU占用的热点。例如我们运行命令perf record -F 99 -p 3261273去分析ceph monitor服务的性能热点,然后运行perf report的到类似下面的输出:
Samples: 601 of event 'cycles:ppp', Event count (approx.): 4918321968
Overhead Command Shared Object Symbol
5.07% tp_fstore_op [kernel.kallsyms] [k] down_read_trylock
4.77% tp_osd_tp ceph-osd [.] _ZSt29_Rb_tree_insert_and_rebalancebPSt18_Rb_tree_node_baseS0_RS_@plt
3.69% fn_appl_fstore ceph-osd [.] OpRequest::_dump_op_descriptor_unlocked
3.58% ms_pipe_read ceph-osd [.] 0x0000000000a2c18f
3.50% tp_fstore_op [kernel.kallsyms] [k] find_busiest_group
3.23% tp_osd_tp [kernel.kallsyms] [k] futex_wait_setup
3.17% fn_odsk_fstore libc-2.17.so [.] __GI_____strtoull_l_internal
2.78% tp_osd_tp [kernel.kallsyms] [k] task_waking_fair
2.52% log [kernel.kallsyms] [k] dequeue_entity
2.31% ms_pipe_read [vdso] [.] __vdso_clock_gettime
2.10% fn_jrn_objstore [kernel.kallsyms] [k] dequeue_entity
2.07% fn_jrn_objstore [kernel.kallsyms] [k] current_kernel_time
2.07% ms_pipe_read libpthread-2.17.so [.] pthread_cond_signal@@GLIBC_2.3.2
2.05% ms_pipe_read libtcmalloc.so.4.2.6 [.] tc_realloc
2.00% tp_fstore_op ceph-osd [.] FileStore::_do_transaction
1.98% ms_pipe_write [kernel.kallsyms] [k] ip_finish_output
1.95% ms_pipe_write ceph-osd [.] PK11_DestroyContext@plt
1.92% ms_pipe_read [kernel.kallsyms] [k] _raw_spin_lock_irqsave
1.91% log [kernel.kallsyms] [k] futex_wait_setup
1.90% log [kernel.kallsyms] [k] get_futex_key_refs.isra.12
1.86% ms_pipe_write [kernel.kallsyms] [k] __nf_conntrack_find_get
1.82% ms_pipe_write [kernel.kallsyms] [k] bnx2x_start_xmit
1.78% tp_fstore_op ceph-osd [.] __snprintf_chk@plt
1.73% log [kernel.kallsyms] [k] __mem_cgroup_count_vm_event
1.72% fn_odsk_fstore libstdc++.so.6.0.19 [.] std::ostream::seekp
1.69% journal_wrt_fin libstdc++.so.6.0.19 [.] std::ios_base::_M_call_callbacks
1.65% journal_wrt_fin libpthread-2.17.so [.] __pthread_mutex_unlock_usercnt
1.65% tp_osd_tp ceph-osd [.] ReplicatedPG::do_op
1.64% journal_wrt_fin [kernel.kallsyms] [k] effective_load.isra.40
1.63% ms_dispatch [kernel.kallsyms] [k] cpuacct_charge
1.60% journal_write [kernel.kallsyms] [k] __blk_recalc_rq_segments
1.58% tp_fstore_op [kernel.kallsyms] [k] cap_inode_setxattr
1.56% tp_osd_tp libstdc++.so.6.0.19 [.] std::operator<< <char, std::char_traits<char> >
1.56% ms_pipe_write [kernel.kallsyms] [k] _raw_spin_lock_irq
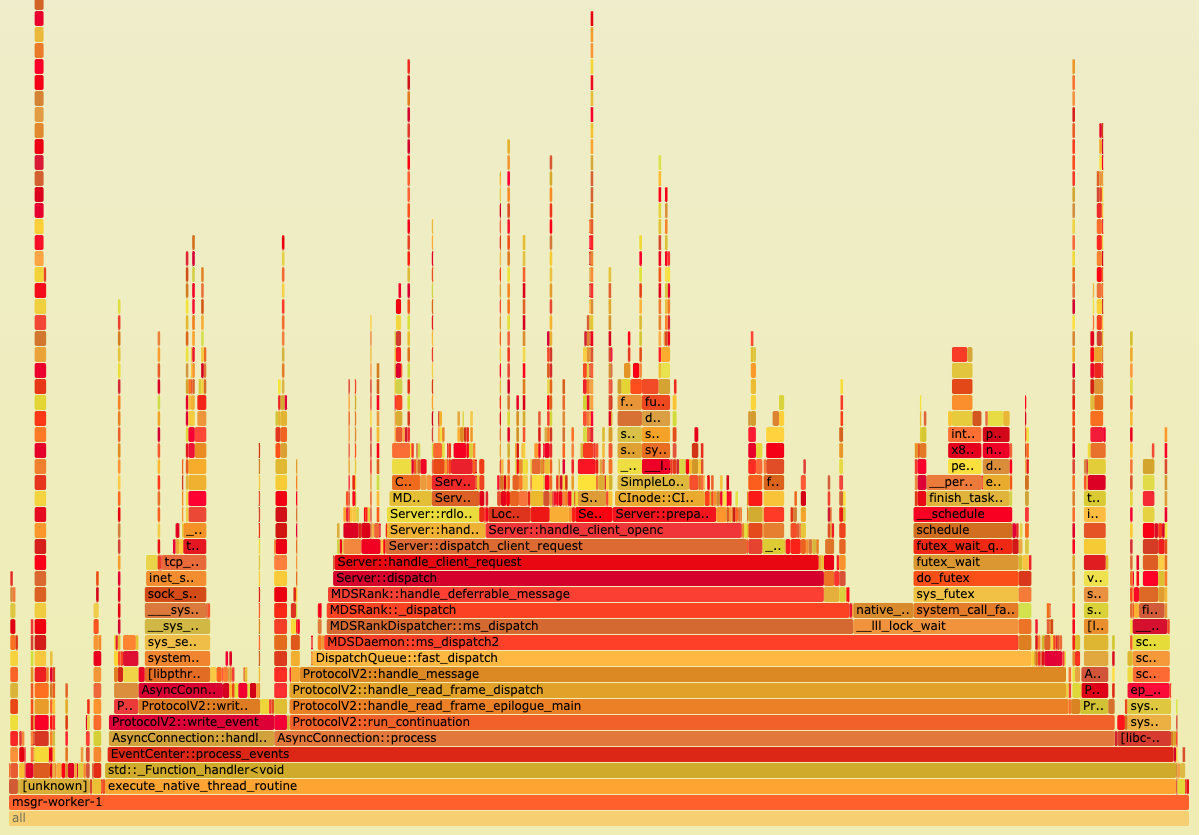
高占用率的函数说明其占用的CPU时间比较多,可能是执行时间长,也可能是调用的频率高。无论哪种情况,都是关注的热点。通过逐个线程,逐级调用分析,找到可优化点,再结合源代码确认是否有问题。perf工具结果也可以有下面更直观和形象化的火焰图展示。
用户态工具
Golang和Java语言编写的程序可以使用语言自身提供的运行时工具,分析程序的内存占用、函数调用序列以及每个函数占用CPU的比率。例如Golang语言用户可以方便的使用pprof工具库,将实时性能采集功能内置到服务中,系统管理员随时通过HTTP调用的方式dump结果,分析线上服务的性能问题。
分析特定事件或者执行顺序
Trace类工具在解决问题时有特殊的作用,它能够帮助用户追踪线上环境的事件、系统(内核)函数调用序列、函数执行延迟、设备IO操作延迟等等。比较典型的工具是:
• Solaris和FreeBSD的Dtrace工具,可参考链接 。
• Linux平台的SystemTap工具,可参考链接 。
• Linux平台的ftrace工具,可参考链接。
• Linux平台的blktrace工具,可参考链接。
其中blktrace可用于跟踪块设备层的IO执行情况,ftrace可用于追踪Linux内核函数执行,分析内核相关的事件,例如确定某进程是否真的接收到某个信号(signal)等等。SystemTap功能更加强大,可以认为是Linux平台的Dtrace,但是要求使用者具备编程能力,并对要分析的源代码有相当的了解。
例如笔者观察到线上某个服务在处理文件系统的rename操作的时候执行性能 非常慢,积累了大量未完成的rename操作,需要确定是那个环节出了问题。笔者使用SystemTap工具进行分析,通过编写Trace脚本,发现rename操作是一个一个顺序完成的,推测可能是本地内核锁的原因。结合操作系统的源代码,确定性能受限于Linux内核的VFS的大锁。因此要通过SystemTap解决实际问题,需要深入了解源代码。工具只是给出有用的线索。
分析网络问题
网络调试是个难点。实际中的网络问题涉及到多台机器,它不同于单个系统的函数调用,而是网络协议的异步异步交互。例如局域网上两个机器配置了同样的IP地址,在应用层表现出来的行为是服务间连接歇性问题。你分析arp协议包,或者在特定机器上通过arp -a会看到不同时间同一个ip地址映射到了不同的物理地址。所以诊断网络问题的第一步是通过基本的配置工具例如ping、arp、ip、route、ethtool等确定配置没有问题。
如果检查配置和基本手段不能解决问题,就得采用终极手段抓包。各个平台都有抓包的软件,例如Windows上的wireshark。在Linux平台,最方便的方式是使用tcpdump工具将网络中传送的数据包完全截获下来分析。它支持针对网络层、协议、主机、网络或端口的过滤,并提供and、or、not等逻辑语句来帮助你去掉无用的信息。要想真正解决问题,需要熟练掌握网络协议。
解决系统问题的成功秘诀是什么?
本篇介绍了撸系统可用的“十八般兵器”,好兵器终须好武艺支撑。笔者认为玩转系统最重要的是工程狮的意志品质。工具再强大,最后都需要工程师发挥主观能动性,不断克服困难。一方面需要工程狮绝对自信,在挫折面前不放弃,坚信问题能够被找到。另一方面需要工程狮非常谦虚,敢于质疑自己的假设和代码正确性。无数老司机们的战斗经验表明,很多展现出微妙的“灵异行为”的Bug,最后往往被证明是个低级错误。